
함수 고급 | ✅저자: 이유정(박사)
🔹 튜플(Tuple)
◽ 괄호 없는 튜플이란?
괄호 없이 쉼표로 구분된 값들은 자동으로 튜플로 처리된다.
</> 예시코드:
x = 10, 20, 30
print(x)
print(type(x))
🖨️ 출력 결과:
(10, 20, 30)
<class 'tuple'>
🔍 해설:
x = 10, 20, 30
→ 괄호가 없어도 쉼표가 있기 때문에 튜플로 간주됨
→ 실제로는x = (10, 20, 30)과 동일print(x)
→ 튜플(10, 20, 30)이 출력됨print(type(x))
→x의 자료형은<class 'tuple'>로 확인됨
⚠️ 주의할 점: 하나의 항목만 있는 튜플을 만들 때는 쉼표 필수!
a = (10) # int
b = (10,) # tuple
</> 예시코드:
a, b, c = 1, 2, 3
print(a + b + c)
print(type((a, b, c)))
🖨️ 출력 결과:
6
<class 'tuple'>
🔍 해설:
-
a, b, c = 1, 2, 3
→ 오른쪽1, 2, 3은 괄호가 없어도 튜플로 인식됨
→ 왼쪽은 튜플 언패킹으로 각 요소를 변수에 할당 -
type((a, b, c))
→ 괄호를 붙였지만(a, b, c)는 여전히 튜플
→ 출력 결과는<class 'tuple'>
📝 문제 1] 다음 코드에서 변수 data의 자료형은 무엇인지 출력해보세요.
data = 7, 14, 21
print(data)
print(type(data))
🖨️ 출력 결과:
(7, 14, 21)
<class 'tuple'>
✅ 정답 코드:
data = 7, 14, 21
print(data)
print(type(data))
🔍 해설:
- 괄호 없이 쉼표로 나열된 값
7, 14, 21은 자동으로 튜플로 처리됩니다. data는(7, 14, 21)이라는 튜플이 되어,type(data)는<class 'tuple'>을 반환합니다.
📝 문제 2] 튜플 언패킹을 이용해 괄호 없이 튜플을 선언하고 변수에 나눠 저장한 후, 모두 더한 값을 출력하세요.
x, y, z = 5, 15, 30
print(x + y + z)
🖨️ 출력 결과:
50
✅ 정답 코드:
x, y, z = 5, 15, 30
print(x + y + z)
🔍 해설:
5, 15, 30은 괄호가 없어도 튜플로 간주되고, 각각x,y,z에 언패킹됩니다.x + y + z는5 + 15 + 30 = 50이 됩니다.
📝 문제 3] 괄호 없는 튜플을 반환하는 함수를 정의하고, 반환된 튜플의 두 번째 요소만 출력하세요.
def get_colors():
return "red", "green", "blue"
colors = get_colors()
print(colors[1])
🖨️ 출력 결과:
green
✅ 정답 코드:
def get_colors():
return "red", "green", "blue"
colors = get_colors()
print(colors[1])
🔍 해설:
-
함수
get_colors()는return "red", "green", "blue"로 세 개의 값을 쉼표로 나열하고 반환 → 자동으로 튜플이 생성됨 -
colors는 튜플("red", "green", "blue")를 받게 되고,colors[1]은"green"을 반환합니다. -
괄호가 없더라도
return구문에서 쉼표만 있으면 튜플이 만들어진다는 것이 포인트입니다.
◽ 튜플과 함수 (함수와 튜플의 활용)
튜플은 함수와 함께 자주 사용되며 다음과 같은 용도로 활용됩니다:
- 함수에서 여러 값을 한 번에 반환할 수 있음
- 튜플 언패킹(Unpacking)으로 여러 변수에 동시에 대입 가능
- 구조화된 고정 데이터 (좌표, RGB, 상태값 등) 표현에 적합
</> 예시코드:
def calc(x, y):
sum_ = x + y
product = x * y
return sum_, product # 튜플 형태로 반환
result = calc(3, 5)
print(result)
- 키워드를 변수로 사용하고 싶을때 특수문자 밑줄을 사용하여 사용할수 있다.
- 의미가 전달되는 변수를 사용할때 유용하다.
🖨️ 출력 결과:
(8, 15)
🔍 해설:
def calc(x, y):
→ 두 개의 값을 받아 계산하는 함수 정의sum_ = x + y,product = x * y
→ 각각 합과 곱 계산return sum_, product
→ 두 값을 쉼표로 구분하여 반환 → 자동으로 튜플 (8, 15) 생성result = calc(3, 5)
→result에는(8, 15)라는 튜플 객체가 저장됨print(result)
→ 튜플 전체 출력됨
◽ 함수에서 괄호 없는 튜플 반환 처리
</> 예시코드:
def get_values():
return 100, 200, 300
result = get_values()
print(result) # ➜ (100, 200, 300)
print(result[1]) # ➜ 200
print(type(result[1])) # ➜ <class 'int'>
print(type(result)) # ➜ <class 'tuple'>
🖨️ 출력 결과:
(100, 200, 300)
200
<class 'int'>
<class 'tuple'>
🔍 해설:
-
return 100, 200, 300
→ 괄호 없이 쉼표로 구분되어 있으므로 튜플 반환 -
result = get_values()
→result는 튜플(100, 200, 300)을 받음 -
result[1]
→ 튜플의 두 번째 요소(200) 접근 → 튜플의 한 요소를 꺼내면 자료형이 됨
◽ 함수가 튜플 반환시, 일부 요소만 활용하여 연산 결과를 출력함수가 반환한 튜플을 변수 세 개로 나누어 저장하고 각각 출력
</> 예시코드:
def get_person():
return "Alice", 28, "Engineer"
name, age, job = get_person()
print(name)
print(age)
print(job)
🖨️ 출력 결과:
Alice
28
Engineer
🔍 해설:
-
return "Alice", 28, "Engineer"
→ 괄호 없이 쉼표로 구분된 값 → 튜플로 자동 반환 -
name, age, job = get_person()
→ 튜플 언패킹(unpacking)으로 변수 3개에 나눠 저장 -
각각 출력하면 문자열, 숫자, 문자열이 출력됨
◽ 함수가 튜플 반환시, 일부 요소만 활용하여 연산 결과를 출력
</> 예시코드:
def get_scores():
return 85, 92, 78, 90
scores = get_scores()
average = (scores[0] + scores[2]) / 2
print("부분 평균:", average)
print("자료형:", type(scores))
🖨️ 출력 결과:
부분 평균: 81.5
자료형: <class 'tuple'>
🔍 해설:
get_scores()는 네 개의 정수형 값을 괄호 없이 반환 → 튜플(85, 92, 78, 90)scores[0]과scores[2]는 각각 85와 78이므로 평균은(85 + 78) / 2 = 81.5type(scores)는<class 'tuple'>을 반환 →scores는 튜플임을 확인 가능
📝문제 1] 함수가 괄호 없이 튜플을 반환합니다. 반환된 튜플을 그대로 출력하세요.
def get_info():
return "Python", 3.11
# 출력 결과가 아래와 같이 나오도록 코드를 완성하세요.
🖨️ 출력 결과:
('Python', 3.11)
✅ 정답 코드:
def get_info():
return "Python", 3.11
info = get_info()
print(info)
🔍 해설:
return "Python", 3.11은 괄호 없이 작성되었지만 튜플로 자동 처리됨- 함수 결과를
info에 저장하고print(info)로 출력하면 튜플 형태로 보임
📝문제 2] 함수가 튜플을 반환합니다. 이 튜플을 변수 3개로 나누어 출력하세요.
def get_student():
return "영희", 17, "여"
# 이름, 나이, 성별을 각각 따로 출력하세요.
🖨️ 출력 결과:
영희
17
여
✅ 정답 코드:
def get_student():
return "영희", 17, "여"
name, age, gender = get_student()
print(name)
print(age)
print(gender)
🔍 해설:
- 함수가 반환한
"영희", 17, "여"는 괄호 없는 튜플 - 변수 3개로 언패킹해서 각각
name,age,gender에 저장 - 각 변수 출력 시 개별 값이 순서대로 출력됨
📝문제 3]다음 함수를 실행한 후, 반환된 튜플 중 첫 번째와 세 번째 숫자의 평균을 구해 출력하세요.
def get_numbers():
return 70, 85, 90
# 평균값을 출력하는 코드를 작성하세요.
🖨️ 출력 결과:
부분 평균: 80.0
✅ 정답 코드:
def get_numbers():
return 70, 85, 90
nums = get_numbers()
average = (nums[0] + nums[2]) / 2
print("부분 평균:", average)
🔍 해설:
get_numbers()는 괄호 없이 튜플(70, 85, 90)을 반환nums[0],nums[2]는 각각 첫 번째(70), 세 번째(90) 값- 평균 계산:
(70 + 90) / 2 = 80.0 print()로 포맷에 맞춰 출력
◽ 튜플 언패킹(Unpacking)으로 여러 변수에 대입하기
◾ 튜플 언패킹이란?
하나의 튜플에 저장된 여러 값을 동시에 여러 변수에 각각 나누어 대입하는 기능입니다.
a, b = (8, 15)
처럼 튜플의 각 요소가 차례대로 변수에 할당됩니다.
◽ 함수의 반환값을 튜플로 받아 언패킹하기
</> 예시코드:
def calc(x, y):
sum_ = x + y
product = x * y
return sum_, product # 튜플 반환
a, b = calc(3, 5)
print("덧셈:", a)
print("곱셈:", b)
🖨️ 출력 결과:
덧셈: 8
곱셈: 15
🔍 해설:
def calc(x, y):
→ 두 값을 받아 합과 곱을 계산하는 함수return sum_, product
→ 튜플(8, 15)형태로 반환됨a, b = calc(3, 5)
→ 튜플 언패킹:(8, 15)의 값을a = 8,b = 15로 나눠 저장print("덧셈:", a)/print("곱셈:", b)
→ 각 변수에 저장된 값을 출력
⚠️ 주의사항
변수 수 ≠ 값의 수 ➜ ValueError 발생
a, b = (1, 2, 3) # ❌ 오류 발생
언패킹 시 _ 또는 * 를 활용한 무시도 가능:
a, _, b = (1, 2, 3) # 2는 무시
a, *rest = (1, 2, 3, 4) # rest = [2, 3, 4]
◽ 세 과목의 점수를 받아 평균과 총점을 반환하고, 언패킹으로 나눠 출력
</> 예시코드:
def get_scores(kor, eng, math):
total = kor + eng + math
average = total / 3
return total, average # 튜플 반환
total_score, avg_score = get_scores(85, 90, 95)
print("총점:", total_score)
print("평균:", avg_score)
✔️ 의사코드
함수 정의: get_scores(국어점수, 영어점수, 수학점수)
총점 = 국어점수 + 영어점수 + 수학점수
평균 = 총점을 3으로 나눈 값
총점과 평균을 함께 반환
함수 호출: get_scores(85, 90, 95)
→ 반환된 값을 total_score와 avg_score에 저장
출력: "총점:", total_score
출력: "평균:", avg_score
🖨️ 출력 결과:
총점: 270
평균: 90.0
🔍 해설:
- 함수
get_scores()는 국어, 영어, 수학 점수를 받아총점과평균을 계산합니다. return total, average는 두 값을 튜플로 반환합니다 →(270, 90.0)total_score, avg_score = get_scores(...)는 언패킹을 통해 각각의 값을 나눠 받습니다.print()를 통해 각각의 변수 값을 확인할 수 있습니다.
◽ 리스트에서 최대값, 최소값, 개수를 계산해서 반환하고, 언패킹 후 일부만 출력
</> 예시코드:
def analyze(numbers):
max_num = max(numbers)
min_num = min(numbers)
count = len(numbers)
return max_num, min_num, count # 튜플 반환
# test용
# data = max_num, min_num, count
# print("data:", type(data))
# return data # 튜플 반환
# 언패킹할 때 중간 값을 무시
maximum, _, total_count = analyze([13, 7, 22, 5, 18])
print("최댓값:", maximum)
print("총 개수:", total_count)
✔️ 의사코드
함수 정의: analyze(숫자들)
최댓값 = 숫자들 중 가장 큰 값
최솟값 = 숫자들 중 가장 작은 값
개수 = 숫자들의 전체 길이
이 세 값을 함께 반환
함수 호출: analyze([13, 7, 22, 5, 18])
→ 반환된 값을 다음 변수에 저장:
- maximum: 최댓값
- _: (최솟값은 사용하지 않으므로 무시)
- total_count: 총 개수
출력: "최댓값:", maximum
출력: "총 개수:", total_count
🖨️ 출력 결과:
최댓값: 22
총 개수: 5
🔍 해설:
analyze()함수는 리스트에서최댓값,최솟값,개수를 계산하여 튜플로 반환합니다 → 예:(22, 5, 5)maximum, _, total_count = ...는 중간 값을 무시(_ 사용)하고 필요한 두 값만 저장print()를 통해 필요한 값만 출력합니다_는 파이썬에서 “나는 이 값은 사용하지 않겠다”는 의미로 자주 사용됩니다.
📝 문제1] 괄호 없이 튜플 만들기
아래 코드에서 data의 자료형은 무엇일까요? 출력값을 통해 확인해보세요.
data = "apple", "banana", "cherry"
print(data)
print(type(data))
🖨️ 출력 결과:
('apple', 'banana', 'cherry')
<class 'tuple'>
✅ 정답 코드:
data = "apple", "banana", "cherry"
print(data)
print(type(data))
🔍 해설:
- 괄호가 없지만 쉼표로 구분된 값이므로
data는 튜플로 인식됨 - 즉,
data = ("apple", "banana", "cherry")와 같은 효과 - 파이썬은 쉼표가 있으면 튜플로 판단함
📝 문제2] 튜플을 함수로 반환하고 저장하기
두 숫자를 더한 값과 곱한 값을 튜플로 반환하는 함수를 만들고, 결과를 result에 저장하여 출력하세요.
🖨️ 출력 결과:
(12, 35)
✅ 정답 코드:
def calc(x, y):
return x + y, x * y # 튜플 반환
result = calc(7, 5)
print(result)
🔍 해설:
- 함수에서
return a, b→ 튜플로 자동 처리됨 result는(12, 35)라는 튜플을 저장- 함수와 튜플은 여러 값 반환할 때 자주 함께 사용됨
📝 문제3] 튜플 언패킹으로 변수 나누기
함수에서 튜플로 반환된 값을 a, b라는 변수에 언패킹하여 각각 출력하세요.
🖨️ 출력 결과:
합계: 10
곱셈: 24
✅ 정답 코드:
def calc(x, y):
return x + y, x * y
a, b = calc(4, 6)
print("합계:", a)
print("곱셈:", b)
🔍 해설:
- 함수
calc()는(10, 24)라는 튜플 반환 a, b = calc(...)로 튜플 언패킹 진행- 각각의 값을 다른 변수로 나누어 출력할 수 있음
📝 문제4] 튜플 언패킹으로 좌표 좌표값 분리
아래와 같은 튜플 coord = (128, 256)이 있을 때,
튜플 언패킹을 통해 x와 y에 각각 저장하고 다음과 같이 출력하세요.
🖨️ 출력 결과:
X 좌표: 128
Y 좌표: 256
✅ 정답 코드:
X 좌표: 128
Y 좌표: 256
🔍 해설:
- 튜플
(128, 256)을 언패킹하여x,y에 각각 저장 - 좌표, 크기, RGB 등 구조화된 정적 데이터를 처리할 때 유용함
- 실무에서 많이 쓰이는 패턴 (ex: 마우스 위치, 이미지 크기 등)
🔹 람다 (lambda)란?
람다(lambda)는 파이썬에서 사용하는 익명 함수(anonymous function)
입니다.
즉, 이름이 없는 간단한 함수를 한 줄로 정의해서 바로 사용할 수 있는
표현식이에요.
◽ 람다는 주로 다음과 같은 상황에서 사용됩니다:
- 일회성으로 간단한 함수를 만들고 싶을 때
map(),filter(),sorted()등의 함수와 함께 사용할 때- 코드 라인을 줄여 가독성을 높이고 싶을 때
📖 문법, 구문(syntax):
lambda 매개변수들: 반환값
lambda: 람다 함수 정의 키워드매개변수: 입력값 (여러 개 가능):뒤의표현식: 반환값 (return 역할)
→ 반드시 한 줄짜리 표현식만 가능 (if, for 같은 문은 사용 불가)
</> 기본예시코드:
# 일반 함수
def add(x, y):
return x + y
# 람다 함수
add_lambda = lambda x, y: x + y
🖨️ 출력결과:
print(add_lambda(3, 5)) # ➜ 8
◽ 다양한 패턴
| 목적 | 람다 함수 예시 | 결과 |
|---|---|---|
| 제곱 | lambda x: x**2 |
4 (입력 2) |
| 더하기 | lambda a, b: a + b |
7 (입력 3, 4) |
| 문자열 길이 | lambda s: len(s) |
5 (입력 "hello") |
| 조건 표현식 | lambda x: "짝수" if x % 2 == 0 else "홀수" |
"짝수" (입력 4) |
◽ 데이터 정렬
</> 예시코드:
data = [(1, 'b'), (3, 'a'), (2, 'c')]
sorted_data = sorted(data, key=lambda x: x[1])
print(sorted_data)
# 출력결과
[(3, 'a'), (1, 'b'), (2, 'c')]
✔️ 의사코드
데이터 목록: (숫자, 문자) 쌍으로 구성된 튜플 리스트 생성
data = [(1, 'b'), (3, 'a'), (2, 'c')]
data를 오름차순으로 정렬한다.
- 정렬 기준: 각 항목의 두 번째 값(문자)
- 즉, 'b', 'a', 'c' 를 기준으로 정렬
- 정렬 결과를 sorted_data에 저장
결과 출력: sorted_data
</> 예시코드: 숫자를 두 배로 만드는 람다 함수
double = lambda x: x * 2
print(double(5))
🖨️ 출력 결과:
10
🔍 해설:
lambda x: x * 2→ x를 받아 2배를 반환하는 익명 함수 생성double은 일반 함수처럼 호출 가능- 람다 함수는 한 줄짜리 단순 계산에 적합
</> 예시코드
students = [
{'name': 'Alice', 'score': 85, 'age': 20},
{'name': 'Bob', 'score': 90, 'age': 22},
{'name': 'Charlie', 'score': 90, 'age': 19},
{'name': 'David', 'score': 80, 'age': 21}
]
# 점수를 내림차순으로, 점수가 같으면 나이를 오름차순으로 정렬
sorted_students = sorted(
students,
key=lambda x: (-x['score'], x['age'])
)
for s in sorted_students:
print(f"{s['name']} - 점수: {s['score']}, 나이: {s['age']}")
✔️ 의사코드
학생 목록: 이름, 점수, 나이가 있는 딕셔너리 리스트 생성
정렬 실행:
- 첫 번째 기준: 점수를 큰 값부터 (내림차순)
- 두 번째 기준: 점수가 같으면 나이를 작은 값부터 (오름차순)
- key 함수는 람다(lambda)를 사용:
각 학생 x에 대해 (-x['score'], x['age']) 반환
정렬된 결과를 하나씩 출력:
이름 - 점수, 나이 형식으로 출력
🖨️ 출력 결과:
Charlie - 점수: 90, 나이: 19
Bob - 점수: 90, 나이: 22
Alice - 점수: 85, 나이: 20
David - 점수: 80, 나이: 21
📝 문제1] 리스트 [3, 5, 1, 4, 2]의 각 숫자를 두 배로 만든 리스트를 출력하세요. (람다 함수 + map)
map과 람다 함수를 사용해 숫자들을 두 배로 만들어 출력해보세요.
🖨️ 출력 결과:
[6, 10, 2, 8, 4]
✅ 정답 결과:
nums = [3, 5, 1, 4, 2]
doubled = list(map(lambda x: x * 2, nums))
print(doubled)
🔍 해설:
lambda x: x * 2→ 각 요소를 두 배로 만드는 람다 함수map()→ 리스트의 각 요소에 람다 함수를 적용list()로 map 객체를 리스트로 변환- 결과:
[3*2, 5*2, 1*2, 4*2, 2*2]→[6, 10, 2, 8, 4]
◽ 두 수를 더하는 람다 함수
</> 예시코드:
add = lambda a, b: a + b
print(add(3, 7))
🖨️ 출력 결과:
10
🔍 해설:
- 매개변수가 2개 이상일 경우 쉼표로 나열
- 일반 함수 정의 없이 바로 사용 가능
◽ 람다 함수를 sorted()와 함께 사용
</> 예시코드:
students = [("유진", 90), ("민수", 75), ("지민", 85)] sorted_students = sorted(students, key=lambda x: x[1]) print(sorted_students)
🖨️ 출력 결과:
[('민수', 75), ('지민', 85), ('유진', 90)]
🔍 해설:
- 튜플의 두 번째 요소(점수)를 기준으로 정렬
lambda x: x[1]은 정렬 기준 key 함수를 간단히 표현
📝 문제1] 튜플 리스트 [("apple", 3), ("banana", 1), ("cherry", 2)]를 과일 개수 기준으로 정렬하세요. (람다 + sorted)
두 번째 요소(개수)를 기준으로 정렬해보세요.
🖨️ 출력 결과:
[('banana', 1), ('cherry', 2), ('apple', 3)]
✅ 정답 결과:
fruits = [("apple", 3), ("banana", 1), ("cherry", 2)]
sorted_fruits = sorted(fruits, key=lambda x: x[1])
print(sorted_fruits)
🔍 해설:
lambda x: x[1]→ 각 튜플에서 두 번째 값(개수)을 기준으로 정렬sorted(..., key=...)→ 리스트 정렬 시 기준 지정- 정렬 순서: 1 → 2 → 3 →
"banana","cherry","apple"
📝 문제2] 학생 리스트 [(“Eve”, 90), (“Dave”, 85), (“Bob”, 92)]를 점수 기준으로 내림차순 정렬하고 이름만 출력하세요.
점수를 기준으로 내림차순 정렬한 후 이름만 뽑아 리스트로 출력해보세요.
🖨️ 출력 결과:
['Bob', 'Eve', 'Dave']
✅ 정답 결과:
students = [("Eve", 90), ("Dave", 85), ("Bob", 92)]
sorted_students = sorted(students, key=lambda x: x[1], reverse=True)
names = [name for name, score in sorted_students]
print(names)
🔍 해설:
key=lambda x: x[1]→ 점수를 기준으로 정렬reverse=True→ 내림차순name for name, score in ...→ 이름만 뽑기 (리스트 컴프리헨션)- 점수 순서: 92 → 90 → 85 → 이름 순서:
"Bob","Eve", `"Dave"
◽ 조건 필터링: 짝수만 추출
</> 예시코드:
nums = [1, 2, 3, 4, 5, 6]
evens = list(filter(lambda x: x % 2 == 0, nums))
print(evens)
🖨️ 출력 결과:
[2, 4, 6]
🔍 해설:
filter()는 조건이 True인 요소만 남김lambda x: x % 2 == 0→ 짝수만 필터링
📝 문제1] 두 숫자를 받아 각각 제곱한 값을 더해주는 람다 함수를 만들어보세요.
# 입력: 3과 4
# 출력: 3² + 4² = 9 + 16 = 25
🖨️ 출력 결과:
25
✅ 정답 코드:
# 두 수의 제곱을 더하는 람다 함수
sum_of_squares = lambda x, y: (x ** 2) + (y ** 2)
print(sum_of_squares(3, 4))
🔍 해설:
-
lambda x, y: (x ** 2) + (y ** 2)는
x와y를 받아 각각 제곱한 뒤 더하는 함수 -
sum_of_squares(3, 4)는3**2 + 4**2 = 9 + 16 = 25 -
람다 함수는 여러 인자를 받아 간단한 계산을 할 때 유용함
📝 문제2] 리스트 [10, 15, 20, 25, 30]에서 20보다 큰 수만 골라 출력하세요. (람다 + filter)
# 조건: 숫자가 20보다 큰 값만 남기기
🖨️ 출력 결과:
[25, 30]
✅ 정답 코드:
nums = [10, 15, 20, 25, 30]
filtered = list(filter(lambda x: x > 20, nums))
print(filtered)
🔍 해설:
-
filter(lambda x: x > 20, nums)는
리스트에서x > 20인 항목만 필터링 -
filter()결과는 반복자이므로list()로 변환해야 출력 가능 -
결과는 20보다 큰
25,30만 추출됨
◽ 함수의 매개변수로 함수 전달하기(고차함수 활용하기)
파이썬에서는 함수도 변수처럼 다른 함수의 인자로 전달할 수 있습니다.
함수는 다른 함수를 인자로 받을 수도 있고,다른 함수를 반환할 수도
있습니다.
◽ 특정 동작을 두 번 실행하는 함수
</> 예시코드:
def run_twice(func):
func()
func()
def greet():
print("안녕하세요!")
run_twice(greet)
✔️ 의사코드
함수 정의: run_twice(함수)
전달받은 함수를 한 번 실행
다시 한 번 실행
함수 정의: greet()
"안녕하세요!" 를 출력
함수 호출: run_twice(greet)
→ greet 함수를 run_twice 함수에 전달
→ greet 함수가 총 2번 실행됨
🖨️ 출력 결과:
안녕하세요!
안녕하세요!
🔍 해설:
run_twice()는 함수를 인자로 받아서 두 번 실행하는 고차함수입니다.greet()함수는 간단한 출력만 수행.run_twice(greet)→greet()를 두 번 호출.- 이 패턴은 반복적인 작업을 추상화할 때 유용합니다.
◽ 리스트의 각 요소에 특정 연산을 적용하는 함수
</> 예시코드:
def apply_operation(numbers, operation):
return [operation(n) for n in numbers]
result = apply_operation([1, 2, 3, 4], lambda x: x * 10)
print(result)
✔️ 의사코드
함수 정의: apply_operation(숫자목록, 연산함수)
각 숫자에 대해 연산함수를 적용한 결과를 리스트로 반환
람다 함수 정의:
입력값 x를 받아서 x에 10을 곱한 결과를 반환
apply_operation 함수 호출:
- 숫자 목록: [1, 2, 3, 4]
- 연산 함수: lambda x: x * 10 (10배로 만드는 함수)
- 각 요소에 연산 함수를 적용
→ 결과: [10, 20, 30, 40]
결과 출력: result
🖨️ 출력 결과:
[10, 20, 30, 40]
🔍 해설:
-
apply_operation()은 리스트와 함수(operation)를 받아
각 요소에 연산을 적용하는 고차함수입니다. -
lambda x: x * 10은 각 숫자를 10배로 만드는 함수입니다. -
리스트 컴프리헨션과 고차함수를 결합해 유연한 데이터 처리가 가능합니다.
◽ 조건에 따라 다른 동작을 반환하는 함수 (함수를 반환하는 고차함수)
</> 예시코드:
def get_discount_func(customer_type):
if customer_type == "VIP":
return lambda price: price * 0.8 # 20% 할인
else:
return lambda price: price * 0.95 # 5% 할인
vip_discount = get_discount_func("VIP")
normal_discount = get_discount_func("Normal")
print("VIP 가격:", vip_discount(10000))
print("일반 가격:", normal_discount(10000))
✔️ 의사코드
함수 정의: get_discount_func(고객_타입)
만약 고객_타입이 "VIP"이면
가격의 80%를 계산하는 할인 함수(lambda)를 반환
그렇지 않으면
가격의 95%를 계산하는 할인 함수(lambda)를 반환
할인 함수 생성:
vip_discount = get_discount_func("VIP")
→ VIP 고객에게 적용할 20% 할인 함수 반환
normal_discount = get_discount_func("Normal")
→ 일반 고객에게 적용할 5% 할인 함수 반환
할인 적용 및 출력:
vip_discount(10000)을 실행하여 할인된 가격 출력
→ 10000 * 0.8 = 8000
normal_discount(10000)을 실행하여 할인된 가격 출력
→ 10000 * 0.95 = 9500
🖨️ 출력 결과:
VIP 가격: 8000.0
일반 가격: 9500.0
🔍 해설:
get_discount_func()는 함수를 반환하는 고차함수입니다.- 고객 유형에 따라 다른 할인 함수를 리턴함
vip_discount = get_discount_func("VIP")→ VIP 전용 할인 함수 반환- 실무에서 가격 정책, 이벤트 전략 등에 많이 사용되는 패턴입니다 (전략 패턴)
</> 람다를 일반함수로 변환한것
def discount(price):
return price * 0.8
📝 문제1] 함수 실행 전후로 로그 메시지를 출력하는 고차 함수를 작성해보세요.
# 어떤 함수를 인자로 받아 실행 전후에 "작업 시작", "작업 완료" 로그를 출력하는
# log_wrapper() 고차 함수를 만들어보세요.
# 작업 대상 함수는 데이터를 처리하거나 메시지를 출력하는 단순 함수입니다.
🖨️ 출력 결과:
[LOG] 작업 시작
데이터 처리 중...
[LOG] 작업 완료
✔️ 의사코드
함수 정의: log_wrapper(함수)
내부 함수 wrapped() 정의
"작업 시작" 로그 메시지를 출력
전달받은 원래 함수를 실행
"작업 완료" 로그 메시지를 출력
내부 함수 wrapped()를 반환
함수 정의: process_data()
"데이터 처리 중..." 메시지를 출력
log_wrapper 함수 호출:
- process_data 함수를 인자로 전달
- 로그 메시지가 추가된 wrapped_process 함수를 반환받음
wrapped_process() 실행:
- [LOG] 작업 시작
- 데이터 처리 중...
- [LOG] 작업 완료
✅ 정답 코드:
def log_wrapper(func):
def wrapped():
print("[LOG] 작업 시작")
func()
print("[LOG] 작업 완료")
return wrapped
def process_data():
print("데이터 처리 중...")
wrapped_process = log_wrapper(process_data)
wrapped_process()
🔍 해설:
log_wrapper(func)전달된 함수 앞뒤로 로그를 출력하는 고차 함수wrapped()내부 함수로, 로그 출력과 함께 원래 함수를 호출log_wrapper(process_data)원래 함수를 감싸서 새로운 동작을 추가한 함수 생성wrapped_process()감싸진 함수 실행 → 실제 로그 + 처리 함수 출력
📝 문제2] 리스트의 각 요소에 10을 곱하는 연산 함수를 만들어 고차함수에 전달하여 새로운 리스트를 만드세요.
# [1, 2, 3]에 대해 각 요소에 10을 곱해 [10, 20, 30]을 출력하세요.
🖨️ 출력 결과:
[10, 20, 30]
✔️ 의사코드
함수 정의: apply_operation(데이터목록, 연산함수)
각 요소 x에 대해 연산함수를 적용한 결과를 리스트로 만들어 반환
람다 함수 정의:
입력값 x에 10을 곱하여 반환하는 익명 함수 생성
apply_operation 함수 호출:
- 데이터 목록: [1, 2, 3]
- 연산 함수: lambda x: x * 10
→ 각 요소에 대해 10을 곱한 결과 리스트 반환
결과 출력: result
✅ 정답 코드:
def apply_operation(data, func):
return [func(x) for x in data]
result = apply_operation([1, 2, 3], lambda x: x * 10)
print(result)
🔍 해설:
apply_operation()은 리스트와 함수를 인자로 받아,
리스트의 각 요소에 함수(func)를 적용하는 고차함수입니다.lambda x: x * 10은 각 요소에 10을 곱하는 함수- 리스트 컴프리헨션을 통해 가공된 새로운 리스트가 생성됩니다.
📝 문제3] 숫자 리스트에 대해 연산 종류를 선택하면 해당 연산을 수행하는 함수를 반환하는 고차함수를 작성하세요.
# 연산 이름을 인자로 주면 해당 연산을 수행하는 함수를 반환하도록 하세요.
# 리스트 [10, 20, 30, 40]에 대해 "sum"을 선택하면 총합 100이 출력되어야 합니다.
🖨️ 출력 결과:
총합: 100
✔️ 의사코드
함수 정의: get_operation(연산_이름)
만약 연산_이름이 "sum"이면
숫자 목록의 총합을 구하는 함수를 반환
아니고, 연산_이름이 "max"이면
숫자 목록의 최댓값을 구하는 함수를 반환
아니고, 연산_이름이 "min"이면
숫자 목록의 최솟값을 구하는 함수를 반환
그 외에는
"지원하지 않는 연산입니다."라는 메시지를 반환하는 함수를 반환
함수 호출: get_operation("sum")
→ 총합을 계산하는 함수를 반환받아 operation 변수에 저장
operation 함수 실행: operation([10, 20, 30, 40])
→ 리스트의 총합 계산 → 결과: 100
결과 출력:
"총합: 100"
✅ 정답 코드:
def get_operation(op_name):
if op_name == "sum":
return lambda nums: sum(nums)
elif op_name == "max":
return lambda nums: max(nums)
elif op_name == "min":
return lambda nums: min(nums)
else:
return lambda nums: "지원하지 않는 연산입니다."
operation = get_operation("sum")
result = operation([10, 20, 30, 40])
print("총합:", result)
🔍 해설:
get_operation(op_name)은 연산 종류를 문자열로 받아 해당하는 함수를 반환하는 고차함수입니다.- 반환된 람다 함수는 리스트를 입력받아
sum(),max(),min()중 하나를 실행합니다. get_operation("sum")은lambda nums: sum(nums)를 반환- 리스트
[10, 20, 30, 40]에 적용하면 총합100이 출력됩니다. - 이 패턴은 사용자 입력에 따라 동작을 분기시켜야 할 때 자주 사용됩니다.
🔹 맵(map) 함수
map() 함수는 리스트, 튜플 등의 시퀀스 자료형의 각 요소에 특정 함수(func)를 적용하여, 변환된 값들을 새로운 시퀀스로 반환하는 함수입니다.
📖 문법, 구문(syntax):
map(function, iterable)
function: iterable의 각 요소에 적용할 함수iterable: 리스트, 튜플 등 반복 가능한 객체
◽ 특징:
- 반환값은
map 객체→ 결과를 보기 위해선list()나tuple()로 변환 필요 - 모든 요소를 "가공/변형"하고 싶을 때 사용
</> 예시코드: 숫자 리스트의 각 값을 2배로 만들기
numbers = [1, 2, 3, 4, 5]
# 리스트의 각 요소를 두 배로 만드는 람다 함수 적용
doubled = list(map(lambda x: x * 2, numbers))
print(doubled)
🖨️ 출력 결과:
[2, 4, 6, 8, 10]
🔍 해설:
numbers = [1, 2, 3, 4, 5]→ 숫자들이 담긴 리스트lambda x: x * 2→ 숫자 하나를 받아 2배로 만드는 함수map(함수, 리스트)→ 리스트 안의 모든 요소에 함수를 적용- 1 →
1 * 2→ 2 - 2 →
2 *2→ 4 - ...
- 1 →
- 결과는
[2, 4, 6, 8, 10] map()의 결과는 기본적으로 map 객체이므로list()로 감싸서 출력해야 실제 값이 보입니다.
🔹 필터(filter) 함수
ilter() 함수는 iterable의 각 요소에 조건 함수를 적용해서,
True를 반환한 값만 남기고 False인 값은 제거하는 함수입니다.
📖 문법, 구문(syntax):
filter(function, iterable)
function: 각 요소에 적용할 조건 함수 → True / False 반환iterable: 반복 가능한 객체
◽ 특징:
- 반환값은
filter 객체→ 결과를 보기 위해선list()나tuple()로 변환 필요 - 필터링(선별)에 사용 → 조건에 맞는 요소만 추출
</> 예시코드: 함수로 문자열의 길이 구하기
# 문자열 리스트
words = ["apple", "banana", "kiwi"]
# 각 단어의 길이를 구하는 람다 함수를 map()에 적용
lengths = list(map(lambda s: len(s), words))
# 결과 출력
print(lengths)
🖨️ 출력 결과:
[5, 6, 4]
🔍 해설:
-
words = ["apple", "banana", "kiwi"]
→ 문자열이 들어 있는 리스트입니다. -
lambda s: len(s)
→ 문자열s하나를 받아서len(s)로 글자 수(길이)를 반환하는 람다 함수입니다. -
map(lambda s: len(s), words)
→words리스트 안의 모든 단어에 대해 위 람다 함수를 하나씩 적용합니다.
즉,"apple"은 5글자,"banana"는 6글자,"kiwi"는 4글자입니다. -
list(...)
→map()함수의 결과는map 객체이므로,list()로 감싸야 실제 리스트 형태로 출력됩니다.
</> 예시코드: 리스트에서 짝수만 골라내기
numbers = [1, 2, 3, 4, 5, 6]
# 짝수만 남기는 람다 함수 적용
evens = list(filter(lambda x: x % 2 == 0, numbers))
print(evens)
🖨️ 출력 결과:
[2, 4, 6]
🔍 해설:
numbers = [1, 2, 3, 4, 5, 6]→ 숫자들이 담긴 리스트lambda x: x % 2 == 0→ 짝수만 True를 반환하는 함수filter(함수, 리스트)→ 리스트 안의 각 요소에 대해:True인 값만 남기고,False인 값은 버림
- 1은 홀수 → ❌
2는 짝수 → ⭕ 3은 홀수 → ❌
4는 짝수 → ⭕ - 결과는
[2, 4, 6] filter()결과도filter 객체이므로list()로 감싸서 출력합니다.
📝 문제1] 리스트 [1, 2, 3, 4, 5]의 각 숫자에 3을 곱한 새로운 리스트를 만들어 출력하세요. (map() 사용)
🖨️ 출력 결과:
[3, 6, 9, 12, 15]
✅ 정답 코드:
numbers = [1, 2, 3, 4, 5]
result = list(map(lambda x: x * 3, numbers))
print(result)
🔍 해설:
lambda x: x * 3→ 입력값x에 3을 곱하는 람다 함수map()→ 리스트의 모든 요소에 람다 함수를 적용list()→map객체를 실제 리스트로 변환해서 결과 출력
📝 문제2] 문자열 리스트 ["hi", "hello", "hey", "goodbye"]에서 길이가 4 이상인 단어만 골라 출력하세요. (filter() 사용)
🖨️ 출력 결과:
['hello', 'goodbye']
✅ 정답 코드:
words = ["hi", "hello", "hey", "goodbye"]
filtered = list(filter(lambda word: len(word) >= 4, words))
print(filtered)
🔍 해설:
lambda word: len(word) >= 4→ 단어 길이가 4 이상일 때만True반환filter()→ 조건이 참(True)인 항목만 남김list()→ 필터 객체를 리스트로 변환해 출력
📝 문제3] 숫자 리스트 [10, 15, 20, 25, 30]에서
- 짝수만 추출(filter)
- 추출된 짝수에 각각 5를 더해서 출력(map)
을 한 줄씩 처리하여 최종 결과를 출력하세요.
🖨️ 출력 결과:
[15, 25, 35]
✅ 정답 코드:
numbers = [10, 15, 20, 25, 30]
result = list(map(lambda x: x + 5, filter(lambda x: x % 2 == 0, numbers)))
print(result)
🔍 해설:
filter(lambda x: x % 2 == 0, numbers)
→ 짝수만 남깁니다:[10, 20, 30]map(lambda x: x + 5, ...)
→ 각 숫자에 5를 더합니다:[15, 25, 35]list()로 최종 결과를 리스트 형태로 출력
🔹 파일처리
파일 처리는 외부 저장소(텍스트 파일 등)에 있는 데이터를 읽거나 쓰는
작업입니다.
파이썬에서는 open() 함수를 사용하여 파일을 열고, 내용을 읽거나 쓸
수 있습니다.
파일을 열면 반드시 닫는(close) 과정이 필요하며, 이를 자동화하려면
with 키워드를 사용합니다.
실무에서는 로그 저장, 설정 파일 불러오기, 데이터 전처리 등 다양한 곳에서 활용됩니다.
◽ 파일 열고 닫기 (open(), close())
open()함수는 텍스트 파일을 열기 위해 사용됩니다.close()함수는 열린 파일을 닫아주기 위해 필수입니다.- 파일을 열고 나면, 반드시 닫아야 메모리 누수나 잠김 오류를 방지할 수 있습니다.
📄 sample.txt 내용:
Hello, Python!
Welcome to file handling.
This is the third line.
</> 예시코드: 파일을 열고 데이터 읽은 후 수동으로 닫기
file = open("sample.txt", "r") # 읽기 모드로 파일 열기
content = file.read() # 파일 내용 전체 읽기
print(content) # 읽은 내용 출력
file.close() # 파일 닫기
🖨️ 출력 결과:
Hello, Python!
Welcome to file handling.
This is the third line.
🔍 해설:
open("sample.txt", "r") : "sample.txt"라는 파일을 읽기 모드("r")로 엽니다.
file.read() : 파일의 전체 내용을 한 번에 읽습니다.
print(content) : 읽은 내용을 화면에 출력합니다.
file.close() : 파일을 명시적으로 닫습니다.닫지 않으면 시스템에 불필요한
자원이 점유될 수 있습니다.
⚠️ 주의 사항:
close()를 호출하지 않으면:- 파일이 시스템 자원을 계속 점유하거나,
- 다른 프로그램에서 파일을 쓸 수 없는 상태로 잠기는 문제가 생깁니다.
- 특히 대규모 프로젝트나 서버 환경에서는
close()누락이 심각한 버그를 유발할 수 있습니다.
◽ with 키워드 사용 (자동으로 닫기)
with open(...) as ...:구문은 파일을 열고 자동으로 닫아주는 구조입니다.file.close()를 직접 쓰지 않아도 되므로 안전하고 오류가 적습니다.- 파일을 열어서 작업한 뒤, 블록이 끝나는 시점에 자동으로 닫히기 때문에 실무에서 가장 추천되는 방식입니다.
</> 예시코드: with 구문으로 파일 열고 읽기
with open("sample.txt", "r") as file:
content = file.read()
print(content)
🖨️ 출력 결과:
Hello, Python!
Welcome to file handling.
This is the third line.
🔍 해설:
with open("sample.txt", "r") as file:
sample.txt 파일을 읽기 모드("r")로 열고, file이라는 이름으로 사용
content = file.read()
파일 전체 내용을 한 번에 읽어서 content 변수에 저장
print(content)
읽어온 내용을 출력
자동으로 닫힘 with 블록이 끝나면 file.close()가 자동 호출됨
📄 sample.txt 내용:
Hello, Python!
Welcome to file handling.
This is the third line.
</> 예시코드: with 구문으로 파일 열고 읽기
with open("sample.txt", "r") as file:
for line in file:
print("줄 내용:", line.strip())
🖨️ 출력 결과:
줄 내용: Hello, Python!
줄 내용: Welcome to file handling.
줄 내용: This is the third line.
🔍 해설:
with open("sample.txt", "r") as file:"sample.txt" 파일을 읽기 모드("r")로 열고, file 객체로 사용for line in file:파일에서 한 줄씩 자동으로 읽음 (반복문으로 처리)line.strip()줄 끝에 있는 줄바꿈 문자 \n 제거print()한 줄씩 출력. "줄 내용: ..." 형태로 보기 좋게 표시자동 닫기with 구문이 끝나면 file.close()가 자동 호출되어 안전하게 닫힘
◽ 텍스트 읽기 (read())
read()함수는 텍스트 파일의 모든 내용을 한 번에 문자열로 읽어오는 함수입니다.- 파일을 열고
read()를 호출하면, 파일 안의 텍스트가 하나의 긴 문자열로 반환됩니다. - 작은 크기의 텍스트 파일을 읽을 때 가장 간단하고 효과적인 방식입니다.
</> 예시코드: 전체 텍스트를 한 번에 읽기
with open("sample.txt", "r") as f:
text = f.read()
print(text)
🖨️ 출력 결과:
Hello, Python!
Welcome to file handling.
This is the third line.
🔍 해설:
open("sample.txt", "r")
"sample.txt" 파일을 읽기 모드("r")로 엽니다.
with ... as f:
파일을 열고, 자동으로 닫기 위해 with 구문 사용
f.read()
파일의 모든 내용을 한 줄의 문자열로 읽어옵니다.
print(text)
문자열을 출력 → 파일 전체 내용이 출력됩니다.
📄 sample.txt 내용:
Hello, Python!
Welcome to file handling.
This is the third line.
</> 예시코드: readline()을 사용하여 파일에서 첫 줄만 읽기
with open("sample.txt", "r") as f:
first_line = f.readline()
print("첫 번째 줄:", first_line.strip())
🖨️ 출력 결과:
첫 번째 줄: Hello, Python!
🔍 해설:
readline()은 파일에서 한 줄만 읽는 함수입니다..strip()은 줄 끝의 줄바꿈 문자(\n)를 제거합니다.with open(...)구조를 사용하면 파일이 자동으로 닫혀서 안전합니다.- 여러 줄이 있는 파일에서 특정 줄만 다루고 싶을 때 유용합니다.
📄 sample.txt 내용:
Hello, Python!
Welcome to file handling.
This is the third line.
</> 예시코드: read()를 사용하여 파일의 앞 10글자만 읽기
with open("sample.txt", "r") as f:
part = f.read(10) # 처음 10글자만 읽기
print("앞부분:", part)
🖨️ 출력 결과:
앞부분: Hello, Pyt
🔍 해설:
read(10)은 파일에서 10개의 문자만 읽습니다.- 전체 파일을 읽지 않고 부분만 읽을 수 있어 메모리 절약이 가능합니다.
- 글자 수로 조절 가능하며, 긴 파일의 미리보기 기능이나 헤더 읽기 등에 활용됩니다.
◽ 텍스트 한 줄씩 읽기 (readline() / readlines() / 반복문)
파이썬에서 텍스트 파일을 줄 단위로 읽는 방법은 크게 3가지가 있습니다:
| 함수/구문 | 설명 |
|---|---|
readline() |
한 줄씩 읽을 때 사용 |
readlines() |
모든 줄을 한꺼번에 리스트 형태로 저장 |
for line in f: |
반복문으로 줄 단위 읽기 (가장 권장) |
📘 예제 파일 내용 (sample.txt): |
Hello, Python!
Welcome to file handling.
This is the third line.
</> 예시코드: 한 줄만 읽기
with open("sample.txt", "r") as f:
line = f.readline()
print(line)
🖨️ 출력 결과 (첫 줄만 출력):
Hello, Python!
🔍 해설:
f.readline()은 파일에서 가장 첫 줄 하나만 읽습니다.- 여러 줄이 있는 파일이라도 한 줄만 출력됩니다.
- 결과에는 줄바꿈 문자(
\n)도 포함되어 있음
</> 예시코드: readlines() – 모든 줄을 리스트로 읽기
with open("sample.txt", "r") as f:
lines = f.readlines()
print(lines)
🖨️ 출력 결과:
['Hello, Python!\n', 'Welcome to file handling.\n', 'This is the third line.']
🔍 해설:
f.readlines()는 모든 줄을 한꺼번에 읽어서 리스트로 반환합니다.- 각 줄은 문자열이 되고, 리스트의 각 요소로 저장됩니다.
- 줄바꿈 문자
\n이 그대로 포함되어 있음
</> 예시코드: for line in f: – 반복문으로 한 줄씩 처리
with open("sample.txt", "r") as f:
for line in f:
print(line.strip()) # 줄바꿈 제거 후 출력
🖨️ 출력 결과:
Hello, Python!
Welcome to file handling.
This is the third line.
🔍 해설:
for line in f:는 파일 객체 자체를 반복문에 사용하여
한 줄씩 자동으로 읽는 방법입니다.line.strip()은 줄 끝의\n줄바꿈 문자를 제거합니다.- 메모리 효율이 높고, 실무에서 가장 많이 사용되는 방식입니다.
🔹 제너레이터 고급
제너레이터(generator)는 값을 한 번에 하나씩 순차적으로 반환하는
이터러블 객체입니다.
return 대신 yield 키워드를 사용하며, 메모리를 아끼면서 데이터를
처리할 수 있는 강력한 함수입니다.
◽ 제너레이터는 특히 다음과 같은 상황에서 유용합니다:
- 매우 큰 데이터 집합을 다룰 때
- 연산 중간에 중단/재개가 필요할 때
- 한 번에 모든 값을 반환하지 않고 필요할 때마다 값을 생성하고 싶을 때
📖 문법, 구문(syntax):
def 함수이름(매개변수):
# 필요한 초기 설정
...
yield 값1
...
yield 값2
...
# 필요 시 반복문 안에서 yield 사용 가능
📖 반복문 안에서 사용하는 일반적인 형태:
def 제너레이터이름(매개변수):
for 항목 in 반복가능한_객체:
# 어떤 처리를 하고
yield 항목 # 값을 하나씩 생성해서 반환
🧾 yield와 제너레이터 함수란? ==일드==
-
yield는return처럼 값을 돌려주지만, 함수를 멈추지 않고 잠시 멈춰둡니다. 다음에 다시 실행하면 이전 멈춘 자리부터 이어서 실행됩니다. -
이렇게
yield를 사용하는 함수를 제너레이터 함수(generator function)라고 부릅니다. -
일반 함수는 한 번에 모든 값을 계산해서 한 번에 반환하지만,
제너레이터 함수는 하나씩 순서대로 값을 만들어서 줄 수 있습니다.
그래서 메모리를 아끼고 효율적입니다. -
이 함수는
for문에서 자동으로 작동합니다.
for문이 내부적으로next()를 사용해서 값을 하나씩 꺼내서 출력해줍니다.
</> 예시코드:
def count_up_to(n):
count = 1
while count <= n:
yield count
count += 1
for num in count_up_to(3):
print(num)
✔️ 의사코드
함수 정의: count_up_to(n)
1부터 n까지 숫자를 하나씩 만들어내는 제너레이터 함수
변수 count를 1로 초기화
반복문 시작: count가 n보다 작거나 같을 때까지 반복
- 현재 count 값을 외부로 전달하고 멈춤 (yield)
- count 값을 1 증가시킴
for 반복문 시작:
count_up_to(3) 제너레이터를 하나씩 반복하면서 num에 저장
- num 값을 출력
🖨️ 출력결과:
1
2
3
✅ 동작순서 예시 (n=3일때)
1. count = 1 → yield 1 → 출력됨
2. count = 2 → yield 2 → 출력됨
3. count = 3 → yield 3 → 출력됨
4. count = 4 → 반복 종료
</> 예시코드: 숫자 3개를 순서대로 생성하는 제너레이터
def simple_gen():
yield 1
yield 2
yield 3
gen = simple_gen()
for value in gen:
print(value)
🖨️ 출력 결과:
1
2
3
🔍 해설:
def simple_gen():
제너레이터 함수 정의. yield를 사용하면 제너레이터가 됨
yield 1
1을 반환하고 함수 실행을 일시 정지
gen = simple_gen()
제너레이터 객체 생성 (아직 실행 X)
for value in gen:
반복문이 자동으로 next()를 호출하며 값을 하나씩 꺼냄
print(value)
1, 2, 3이 차례로 출력됨
🔁 내부 작동 방식:
gen = simple_gen() # 준비만 함 (실행 X)
next(gen) # yield 1 → 출력: 1
next(gen) # yield 2 → 출력: 2
next(gen) # yield 3 → 출력: 3
next(gen) # StopIteration 예외 발생 (끝)
for문은 위 next() 호출 과정을 자동으로 반복하며 처리합니다.
📝 파일에서 한 줄씩 읽어 처리하는 제너레이터
- 수천 줄짜리 대용량 파일을 한꺼번에 메모리에 올리면 부담이 큽니다.
- 제너레이터를 사용하면 한 줄씩 처리하면서 메모리 효율을 높일 수 있습니다.
</> 예시 코드:
def read_lines(filename):
with open(filename, "r", encoding="utf-8-sig") as f:
for line in f:
yield line.strip() # 줄 끝 개행문자 제거 후 반환
# 제너레이터 사용
for line in read_lines("log.txt"):
print("처리 중:", line)
as f는 열린 파일 객체를 변수 f에 저장해서 사용합니다.
📄 log.txt 내용:
[INFO] 서버 시작
[INFO] 사용자 로그인
[ERROR] 접속 실패
🖨️ 출력 결과:
처리 중: [INFO] 서버 시작
처리 중: [INFO] 사용자 로그인
처리 중: [ERROR] 접속 실패
🔍 해설:
def read_lines(filename):
파일 이름을 받아 줄 단위로 데이터를 넘겨주는 제너레이터 함수
with open(...)
파일을 열고 자동으로 닫기 위해 사용
for line in f:
파일을 줄 단위로 반복
yield line.strip()
각 줄을 반환하면서 함수 실행을 일시 중단하고, 줄바꿈 제거
for line in read_lines(...):
제너레이터를 사용해 줄을 하나씩 꺼내서 처리
📝 문제1] 파일의 각 줄을 한 줄씩 출력하는 제너레이터 함수를 만들어보세요.
# read_lines() 제너레이터 함수를 정의하여,
# "sample.txt" 파일의 내용을 한 줄씩 읽고 출력하세요.
🖨️ 출력 결과:
첫 번째 줄입니다.
두 번째 줄입니다.
세 번째 줄입니다.
✅ 정답 코드:
def read_lines(filename):
with open(filename, "r", encoding="utf-8") as f:
for line in f:
yield line.strip()
for line in read_lines("sample.txt"):
print(line)
🔍 해설:
yield는 값을 하나씩 외부로 보내고 함수 실행을 잠깐 멈춤with open()으로 파일을 안전하게 열고 자동으로 닫히도록 함line.strip()은 줄 끝의\n제거for line in read_lines(...)는 한 줄씩 처리하는 반복문
📝 문제2] 숫자 파일에서 짝수만 골라 출력하는 제너레이터를 만들어보세요.
# numbers.txt 파일에 숫자가 줄마다 한 개씩 있다고 가정하고,
# 짝수만 골라서 출력하는 even_numbers() 제너레이터 함수를 작성하세요.
🖨️ 출력 결과:
2
4
6
✅ 정답 코드:
def even_numbers(filename):
with open(filename, "r", encoding="utf-8") as f:
for line in f:
number = int(line.strip())
if number % 2 == 0:
yield number
for n in even_numbers("numbers.txt"):
print(n)
🔍 해설:
- 파일의 각 줄을
int로 변환하여 짝수인지 확인 - 짝수면
yield로 외부로 보내 출력 - 제너레이터는 짝수만 필터링하므로 메모리 효율이 좋음
- 파일이 커도 필요한 숫자만 처리하므로 실무에서 유용함
📝 문제3] 제너레이터로 파일의 줄 수를 세되, 중간에 "STOP"이라는 문장이 있으면 멈추세요.
# count_until_stop(filename) 제너레이터 함수를 작성하여,
# "STOP"이라는 문장이 나올 때까지 줄을 세고 출력하세요.
🖨️ 출력 결과:
[1] 시작합니다.
[2] 데이터를 처리 중입니다.
[3] STOP
(중단됨)
✔️ 의사코드
함수 정의: count_until_stop(파일명)
파일을 UTF-8 인코딩으로 연다
줄 번호를 나타내는 변수 count를 1로 초기화
파일의 각 줄을 반복하면서 다음을 수행:
- 줄 끝의 줄바꿈 문자(\n)를 제거하고 text 변수에 저장
- "[줄 번호] 줄 내용" 형태로 외부에 넘긴다 (yield)
- 만약 줄 내용이 "STOP"이면
→ 제너레이터를 종료한다 (return)
- 그렇지 않으면 count 값을 1 증가시킨다
함수 호출: count_until_stop("log.txt")
반복문으로 제너레이터에서 한 줄씩 꺼내어 출력한다
제너레이터가 종료된 후에는 "(중단됨)"을 출력한다
✅ 정답 코드:
def count_until_stop(filename):
with open(filename, "r", encoding="utf-8") as f:
count = 1
for line in f:
text = line.strip()
yield f"[{count}] {text}"
if text == "STOP":
return # 제너레이터 종료
count += 1
for line in count_until_stop("log.txt"):
print(line)
print("(중단됨)")
🔍 해설:
- 각 줄 앞에 번호를 붙이고 출력 (
[1],[2]형태) - 줄 내용이
"STOP"이면return으로 제너레이터 종료 yield는 한 줄씩 외부로 넘기고, 다음 줄에서 이어서 실행됨- 제너레이터는 필요한 만큼만 처리하고 멈추는 데 적합함
◽ 리스트 vs 제너레이터 비교
리스트(list)는 모든 값을 한꺼번에 만들어서 메모리에 저장합니다.제너레이터(generator)는 필요할 때마다 값을 하나씩 생성합니다.- 수십만 개의 데이터를 다룰 때는 제너레이터가 메모리 효율이 훨씬 좋습니다.
</> 예시코드:
# 리스트 생성 함수 (메모리에 전부 저장)
def make_list(n):
return [i for i in range(n)]
# 제너레이터 생성 함수 (값을 하나씩 생성)
def make_gen(n):
for i in range(n):
yield i
✔️ 의사코드
함수 정의: make_list(n)
0부터 n-1까지의 숫자를 하나의 리스트에 모두 저장해서 반환한다
→ 즉, [0, 1, 2, ..., n-1] 형태의 리스트를 만들어 한 번에 돌려준다
함수 정의: make_gen(n)
0부터 n-1까지 숫자를 하나씩 생성하는 제너레이터 함수
for 반복문으로 i를 0부터 n-1까지 순서대로 생성하면서
yield i 를 실행하여
→ 현재 숫자를 외부로 보내고 함수 실행을 잠시 멈춘다
이 함수는 호출 시 리스트처럼 모든 값을 한꺼번에 만들지 않고,
필요할 때마다 하나씩 꺼낼 수 있다
🔍 두개 함수 차이:
| 항목 | make_list(n) | make_gen(n) |
|---|---|---|
| 동작 방식 | 모든 값을 미리 메모리에 저장 | 값을 하나씩 필요할 때 생성 (yield) |
| 반환 형태 | 리스트 (예: [0, 1, 2, 3]) |
제너레이터 객체 (반복 가능한 값 생성기) |
| 메모리 사용량 | n이 클수록 메모리 많이 사용 | 매우 효율적, 큰 데이터에도 적합 |
| 실행 구조 | return 으로 즉시 전체 리스트 반환 | yield로 하나씩 반환하며 중간 상태 유지 가능 |
📝 문제1] 리스트와 제너레이터의 차이를 출력해보세요.
# make_list(n) 함수는 리스트를 반환하고,
# make_gen(n) 함수는 제너레이터를 반환합니다.
# 두 함수를 호출하고 각각의 자료형(type)을 출력해보세요.
🖨️ 출력 결과:
리스트 자료형: <class 'list'>
제너레이터 자료형: <class 'generator'>
✅ 정답 코드:
def make_list(n):
return [i for i in range(n)]
def make_gen(n):
for i in range(n):
yield i
lst = make_list(5)
gen = make_gen(5)
print("리스트 자료형:", type(lst))
print("제너레이터 자료형:", type(gen))
🔍 해설:
make_list()는 전체 숫자를 담은 리스트를 반환하므로 자료형이<class 'list'>임make_gen()는yield를 사용하므로 제너레이터 객체(<class 'generator'>)를 반환함type()은 자료형을 확인할 수 있는 함수로, 리스트와 제너레이터의 차이를 쉽게 비교할 수 있음
📝 문제2] 리스트와 제너레이터의 메모리 사용 차이를 출력해보세요.
# sys.getsizeof() 함수를 이용해 make_list()와 make_gen()이
# 각각 1,000,000개의 숫자를 처리할 때 얼마나 메모리를 사용하는지 비교해보세요.
🖨️ 출력 결과:
리스트 메모리 사용량: 8448720 bytes
제너레이터 메모리 사용량: 112 bytes
✅ 정답 코드:
import sys
def make_list(n):
return [i for i in range(n)]
def make_gen(n):
for i in range(n):
yield i
lst = make_list(1_000_000)
gen = make_gen(1_000_000)
print("리스트 메모리 사용량:", sys.getsizeof(lst), "bytes")
print("제너레이터 메모리 사용량:", sys.getsizeof(gen), "bytes")
🔍 해설:
sys.getsizeof()는 객체가 차지하는 메모리 크기를 바이트 단위로 측정해주는 함수임- 리스트는 모든 값을 한꺼번에 메모리에 저장하므로 사용량이 매우 큼
- 제너레이터는 값을 하나씩 만들기 때문에 매우 적은 메모리만 사용함
- 제너레이터는 대용량 데이터 처리에 매우 적합함
</> 예시코드: 제너레이터 표현식 (Generator Expression)
gen = (x ** 2 for x in range(5))
print(list(gen))
✔️ 의사코드
1. 숫자 0부터 4까지 반복하면서, 각 숫자의 제곱을 계산한다
→ 예: 0**2, 1**2, 2**2, 3**2, 4**2 → 0, 1, 4, 9, 16
2. 이 계산 결과들을 저장하지 않고, 하나씩 만들어주는 **제너레이터 표현식**을 만든다
→ gen 변수에 저장됨
3. list(gen)를 사용하여, 제너레이터에서 값을 **모두 꺼내어 리스트로 변환**한다
→ 결과 리스트: [0, 1, 4, 9, 16]
4. 리스트를 출력한다
🖨️ 출력 결과:
[0, 1, 4, 9, 16]
🔍 해설:
-
(x ** 2 for x in range(5))는 제너레이터 표현식이며,yield없이 제너레이터를 만들 수 있는 간단한 문법입니다. -
list(gen)을 사용하면, 제너레이터 안의 값들을 한 번에 모두 꺼내서 리스트로 변환합니다. -
제너레이터는 한 번만 사용할 수 있고, 이후에는 비어 있게 됩니다.
| 항목 | 설명 |
|---|---|
yield 키워드 |
return과 비슷하지만 실행 중단 상태 유지 |
| 제너레이터의 장점 | 메모리 효율 우수, 한 번에 하나씩 데이터 처리 |
next() 함수 |
제너레이터의 다음 값 반환, 끝나면 StopIteration 발생 |
| 제너레이터 표현식 | (x for x in iterable) 형태로 간결하게 제너레이터 생성 가능 |
| 실무 활용 예 | 대용량 로그 처리, 무한 수열 생성, 실시간 데이터 스트리밍 등에서 사용 |
🔹 리스트 함수의 key 키워드 매개변수
파이썬의 리스트 관련 함수(특히 sorted(), max(), min() 등)는
정렬이나 비교 기준을 커스터마이징할 수 있도록
key라는 키워드 매개변수(keyword argument)를 제공합니다.
key 매개변수에는 함수(또는 람다)를 전달하여
정렬 기준, 비교 기준 등을 직접 설정할 수 있습니다.
</> 예시코드: 문자열 길이로 정렬하기
words = ["apple", "banana", "kiwi", "grape"]
sorted_words = sorted(words, key=len)
print(sorted_words)
✔️ 의사코드
1. 문자열들이 들어 있는 리스트 words를 만든다
→ 예: ["apple", "banana", "kiwi", "grape"]
2. sorted() 함수를 사용해 문자열 리스트를 정렬한다
→ 정렬 기준은 key=len 으로 설정
→ 각 문자열의 길이(len)를 기준으로 정렬함
3. 정렬된 결과를 sorted_words에 저장한다
→ 새 리스트가 만들어짐 (원본은 그대로 유지됨)
4. sorted_words를 출력한다
🖨️ 출력 결과:
['kiwi', 'apple', 'grape', 'banana']
🔍 해설:
-
sorted()는 리스트를 정렬하지만, 원래 리스트는 바꾸지 않고 새로운 리스트를 만들어줍니다. -
key=len은len()함수를 이용해서, 각 단어의 길이를 기준으로 정렬하라는 뜻입니다. -
len("kiwi") → 4,len("apple") → 5,len("grape") → 5,len("banana") → 6 -
그래서 짧은 단어부터 긴 단어 순으로 정렬된 결과가 나옵니다.
</> 예시코드: 튜플 리스트에서 점수 기준으로 정렬하기
students = [("유진", 90), ("민수", 75), ("지민", 85)] sorted_students = sorted(students, key=lambda x: x[1]) print(sorted_students)
✔️ 의사코드
1. 학생 이름과 점수가 들어 있는 튜플 리스트를 만든다
→ 예: [("유진", 90), ("민수", 75), ("지민", 85)]
2. sorted() 함수를 사용해서 리스트를 정렬한다
→ 정렬 기준: 각 튜플의 두 번째 요소 (점수)
→ lambda x: x[1]은 "x 튜플의 두 번째 값(점수)"를 꺼내는 함수
3. 정렬된 결과를 sorted_students에 저장한다
→ 점수가 낮은 순서대로 정렬됨
4. 정렬된 리스트를 출력한다
🖨️ 출력 결과:
[('민수', 75), ('지민', 85), ('유진', 90)]
🔍 해설:
-
각 항목은
(이름, 점수)처럼 두 개의 값을 가진 튜플입니다. -
sorted()는 리스트를 정렬해주는 함수이며,key를 설정하면 어떤 기준으로 정렬할지 직접 지정할 수 있어요. -
lambda x: x[1]은 각 튜플에서 두 번째 값인 점수(x[1])만 꺼내서 그걸 기준으로 정렬하라는 뜻입니다. -
점수가 작은 것부터 큰 것 순서로 정렬되어 출력됩니다.
-
원래 리스트는 바뀌지 않고, 새로운 정렬된 리스트가 만들어집니다.
📝 문제1] 문자열 리스트를 길이 기준으로 정렬하세요.
# 문자열 리스트에서 단어의 길이가 짧은 순으로 정렬해보세요.
words = ["car", "elephant", "dog", "ant"]
🖨️ 출력 결과:
['car', 'dog', 'ant', 'elephant']
✅ 정답 코드:
words = ["car", "elephant", "dog", "ant"]
sorted_words = sorted(words, key=len)
print(sorted_words)
🔍 해설:
-
sorted()는 리스트를 정렬해주는 함수입니다. -
key=len은 각 단어의 길이를 기준으로 정렬하라는 뜻입니다. -
정렬 결과는 짧은 단어 → 긴 단어 순서로 나옵니다.
-
원래 리스트는 바뀌지 않고, 새로운 정렬된 리스트가 생성됩니다.
📝 문제2] 학생들의 (이름, 점수) 튜플 리스트를 점수 기준으로 오름차순 정렬하세요.
# 튜플 리스트에서 점수를 기준으로 오름차순 정렬하세요.
students = [("수민", 100), ("지수", 88), ("태영", 95)]
🖨️ 출력 결과:
[('지수', 88), ('태영', 95), ('수민', 100)]
✅ 정답 코드:
students = [("수민", 100), ("지수", 88), ("태영", 95)]
sorted_students = sorted(students, key=lambda x: x[1])
print(sorted_students)
🔍 해설:
-
각 항목은
(이름, 점수)형식의 튜플입니다. -
lambda x: x[1]은 각 튜플의 두 번째 값인 점수를 꺼냅니다. -
sorted(..., key=...)는 이 값을 기준으로 정렬합니다. -
결과는 점수가 작은 순서부터 정렬되어 출력됩니다.
📝 문제3] 학생 이름과 점수를 담은 튜플 리스트를 점수는 내림차순, 점수가 같다면 이름 오름차순으로 정렬하세요.
# 동일 점수가 있을 경우 이름순으로 정렬되도록 코드를 작성하세요.
students = [("지수", 90), ("민호", 100), ("수민", 90), ("예진", 95)]
🖨️ 출력 결과:
[('민호', 100), ('예진', 95), ('수민', 90), ('지수', 90)]
✅ 정답 코드:
students = [("지수", 90), ("민호", 100), ("수민", 90), ("예진", 95)]
sorted_students = sorted(students, key=lambda x: (-x[1], x[0]))
print(sorted_students)
🔍 해설:
lambda x: (-x[1], x[0])는 정렬 기준을 2개 설정한 것입니다.-x[1]: 점수를 내림차순으로 정렬합니다 (음수로 만들기)x[0]: 점수가 같을 때는 이름을 알파벳 순으로 정렬
sorted()는 여러 기준으로 정렬할 수 있으며, 먼저 온 기준이 우선 적용됩니다.- 이 방식은 실무에서도 자주 사용하는 다중 정렬 패턴입니다.
</> 예시코드: 숫자 리스트를 절댓값 기준으로 정렬
nums = [-3, 1, -7, 4, -2]
sorted_nums = sorted(nums, key=abs)
print(sorted_nums)
✔️ 의사코드
1. 정수들로 이루어진 리스트 nums를 만든다
→ 예: [-3, 1, -7, 4, -2]
2. sorted() 함수를 사용해서 리스트를 정렬한다
→ key=abs를 사용하여, 각 숫자의 절댓값을 기준으로 정렬
3. 정렬된 결과를 sorted_nums에 저장한다
→ 즉, |-3|=3, |1|=1, |-7|=7, |4|=4, |-2|=2 → 절댓값 기준으로 정렬
4. 결과를 출력한다
🖨️ 출력 결과:
[1, -2, -3, 4, -7]
🔍 해설:
-
abs()는 숫자의 절댓값(음수를 양수로 바꾼 값)을 구하는 파이썬 내장 함수입니다.- 예:
abs(-3)→ 3,abs(4)→ 4
- 예:
-
sorted(..., key=abs)는 리스트를 정렬할 때 절댓값을 기준으로 비교하라는 의미입니다. -
이 경우 정렬 기준은 절댓값이지만, 숫자의 부호는 그대로 유지됩니다.
-
그래서 실제 값은 유지되지만, 절댓값이 작은 수부터 큰 수까지 정렬됩니다.
</> 예시코드:] min()과 max()에서도 key 사용 가능
data = ["aaa", "bb", "c"]
shortest = min(data, key=len)
longest = max(data, key=len)
print("가장 짧은 단어:", shortest)
print("가장 긴 단어:", longest)
✔️ 의사코드
1. 문자열이 들어 있는 리스트 data를 만든다
→ 예: ["aaa", "bb", "c"]
2. min(data, key=len) 을 사용하여
→ 문자열의 길이를 기준으로 가장 짧은 단어를 찾는다
→ 결과를 shortest 변수에 저장
3. max(data, key=len) 을 사용하여
→ 문자열의 길이를 기준으로 가장 긴 단어를 찾는다
→ 결과를 longest 변수에 저장
4. shortest와 longest를 출력한다
🖨️ 출력 결과:
가장 짧은 단어: c
가장 긴 단어: aaa
🔍 해설:
-
min()과max()는 가장 작은 값이나 큰 값을 찾는 함수예요. -
원래는 숫자에서 많이 쓰이지만,
key=를 쓰면 비교 기준을 바꿀 수 있습니다. -
여기서는
key=len을 사용해서, 문자열의 길이로 비교하게 만든 거예요."c"는 길이가 1로 가장 짧고,"aaa"는 길이가 3으로 가장 깁니다.
-
따라서
min(data, key=len)은"c"를,max(data, key=len)은"aaa"를 반환합니다.
📝 문제1] 숫자 리스트를 절댓값 기준으로 오름차순 정렬해보세요.
# 음수가 섞여 있는 리스트를 절댓값 기준으로 정렬하세요.
nums = [-5, -1, 3, -10, 2]
🖨️ 출력 결과:
[-1, 2, 3, -5, -10]
✅ 정답 코드:
nums = [-5, -1, 3, -10, 2]
sorted_nums = sorted(nums, key=abs)
print(sorted_nums)
🔍 해설:
-
abs()는 숫자의 절댓값을 구하는 함수입니다. -
key=abs를 사용하면 절댓값이 작은 순서로 정렬됩니다. -
실제 값은 그대로 유지되지만, 정렬 기준만 절댓값입니다.
-
sorted()는 원래 리스트를 바꾸지 않고 새 리스트를 만들어 반환합니다.
📝 문제2] min()을 사용해 절댓값이 가장 작은 수를 찾아보세요.
# 아래 리스트에서 절댓값이 가장 작은 수를 찾아 출력하세요.
nums = [-8, -2, 5, -1, 7]
🖨️ 출력 결과:
절댓값이 가장 작은 수: -1
✅ 정답 코드:
nums = [-8, -2, 5, -1, 7]
min_num = min(nums, key=abs)
print("절댓값이 가장 작은 수:", min_num)
🔍 해설:
-
min()은 리스트에서 가장 작은 값을 반환합니다. -
key=abs를 사용하면 절댓값을 기준으로 비교합니다. -
abs(-1)= 1 이므로, 가장 작은 절댓값을 가진-1이 결과로 출력됩니다. -
min()은 리스트 전체에서 하나의 최솟값만 반환합니다.
📝 문제3] max()를 사용해 절댓값이 가장 큰 수를 찾아 출력하세요.
단, 절댓값이 같은 경우는 양수를 우선 선택하세요.
# 예: -9와 9는 절댓값이 같지만, 9를 출력해야 함
nums = [-9, 5, 9, -3, -4]
🖨️ 출력 결과:
절댓값이 가장 큰 수: 9
✅ 정답 코드:
nums = [-9, 5, 9, -3, -4]
max_num = max(nums, key=lambda x: (abs(x), -x))
print("절댓값이 가장 큰 수:", max_num)
🔍 해설:
-
key=lambda x: (abs(x), -x)는 정렬 기준이 2가지입니다:abs(x)→ 절댓값이 큰 것이 우선-x→ 절댓값이 같을 경우 양수를 우선 (-9 < -x→9 > -9)
-
이렇게 하면
-9와9중 절댓값은 같지만, 양수인9가 선택됩니다. -
lambda를 활용하면 복잡한 비교 조건도 쉽게 구현할 수 있습니다.
🔹 스택, 힙
프로그램이 실행되면, 변수나 함수의 데이터를 저장할 공간이 필요합니다.
이때 사용하는 두 가지 대표적인 메모리 구조가 스택(Stack)과
힙(Heap)입니다.
◽ 스택메모리란?
일시적으로 잠깐 필요한 데이터를 빠르게 저장하고 꺼내는 공간
스택 메모리는 함수나 코드 실행 중에 잠깐 필요한 데이터를 저장하는 공간입니다.
함수를 부를 때마다 잠깐 꺼내 쓰고, 끝나면 자동으로 사라집니다.
🧱 일상 비유: 책 쌓기, 접시쌓기
- 책을 한 권씩 위에 쌓고, 꺼낼 땐 맨 위부터 꺼내죠? 접시도 마찬가지고요.
- 이것이 스택 구조 (Last-In First-Out, LIFO)라고 합니다.
- 가장 나중에 넣은 것이 가장 먼저 나간다는 의미입니다.
(맨 위) 함수 C 실행
함수 B 실행
(맨 아래) 함수 A 실행
→ 함수 A가 B를 부르고, B가 C를 부르면
→ 실행 순서는 A → B → C,
→ 끝나는 순서는 C → B → A
운영체제 OS가 제공하는 메모리 공간을 시각화 표현한 것입니다.
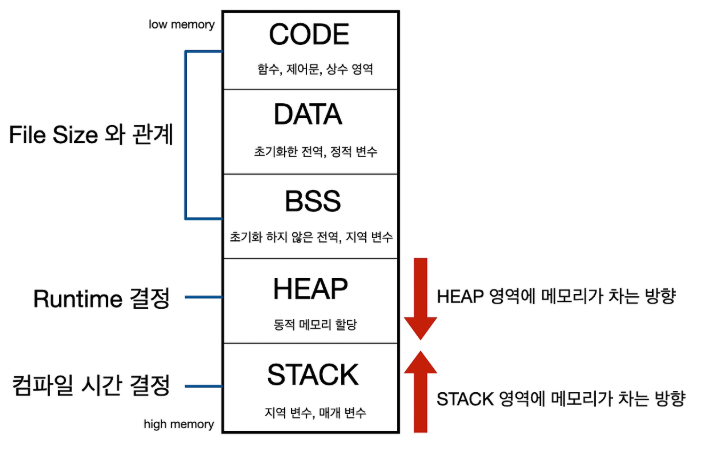
-
함수가 실행되면 스택에 올라가고, 끝나면 스택에서 내려옵니다.
-
스택 영역은 메모리에서 위쪽 주소부터 아래쪽 방향으로 쌓입니다.
-
재귀 호출처럼 함수를 계속 호출하면, 스택이 계속 쌓이다가
너무 많아지면 오류(RecursionError)가 발생할 수 있습니다.
</>예시코드:
def greet():
message = "안녕하세요!" # 지역 변수 message는 스택에 저장됨
print(message)
greet()
greet()가 호출되면 스택에 저장됨- 함수가 끝나면
message도 자동으로 사라짐
◽ 힙 메모리란?
오래 유지하거나 크기가 정해지지 않은 데이터를 저장하는 공간입니다.
사용자가 직접 관리해야 해요 (생성, 삭제)
동적으로 할당됨 (리스트, 딕셔너리, 객체 등 대부분이 여기에 저장됨)
참조(주소)를 통해 접근합니다.
파이썬에서는 사용하지 않게 된 데이터(객체)는 자동으로 메모리에서 지워집니다. 이 과정을 도와주는 기능을 '가비지 컬렉터(Garbage Collector)'라고 부릅니다.
- HEAP은 아래에서 위로 자라며,
- STACK은 위에서 아래로 자랍니다.
- 중간에서 둘이 만나면 메모리 부족(충돌)이 발생합니다.
🧱 일상 비유: 냉장고는 음식을 넣어두고, 나중에 꺼내 쓸 수 있는 공간이에요. 필요할 때 직접 넣고, 꺼내야 할 때 꺼내야 해요. 너무 오래 두고 잊어버리면 냉장고가 꽉 차고, 정리가 필요하죠? 파이썬의 가비지 컬렉터는 냉장고 청소부처럼 더 이상 안 쓰는 음식(데이터)을 자동으로 버려줘요.
동적 메모리 할당이란 정확히 얼마나 필요한지 모르니까, 실행 중에 필요한 만큼만 메모리를 달라고 요청해서 쓰는 것"이에요.
✅ 실제 데이터 상황 예시 1️⃣ 리스트(list)나 딕셔너리(dict) 만들기
data = [] # 빈 리스트 생성
data.append(1) # 동적으로 메모리 증가
data.append(2)
- 리스트는 처음에 작게 시작하지만,
.append()할 때마다 메모리가 조금씩 늘어납니다. - 이게 바로 실행 중에 필요한 만큼 동적 메모리 할당이 일어나는 예예요.
2️⃣ 사용자 입력을 받아서 저장할 때
n = int(input("몇 명 입력할까요? "))
names = []
for _ in range(n):
names.append(input("이름: "))
- 몇 명을 입력할지 코드 작성 시에는 알 수 없어요.
- 그래서 실행 중에 입력된 개수만큼 메모리를 동적으로 확보하게 됩니다.
- 이때 리스트
names는 계속 확장되며 힙에 메모리가 추가로 할당돼요.
3️⃣ 웹사이트에서 이미지나 데이터를 불러올 때
response = requests.get("https://example.com/image.jpg")
image_data = response.content
- 이미지 크기는 고정되어 있지 않기 때문에, 받아온 데이터의 크기만큼 메모리가 자동으로 할당됨
- 이 역시 동적으로 메모리를 확보하는 과정이에요
4️⃣ 딥러닝에서 입력 크기나 배치 사이즈에 따라 메모리 자동 사용
model.fit(X_train, y_train, batch_size=64)
- 학습할 때 배치 크기나 모델 크기에 따라 메모리 사용량이 달라짐
- GPU/CPU가 동적으로 메모리를 요청해서 확보합니다
</>예시코드:
people = ["영희", "철수"] # 리스트는 힙에 저장됨
people은 힙에 저장되고, 참조(people변수)를 통해 접근함- 참조가 사라지면 가비지 컬렉터가 자동으로 제거함
</> 예시코드: 리스트가 힙에 저장되는 구조
def make_list():
data = [1, 2, 3] # 리스트는 힙에 저장됨
print("리스트 내용:", data)
make_list()
🖨️ 출력 결과:
리스트 내용: [1, 2, 3]
🔍 해설:
-
data = [1, 2, 3]는 리스트를 생성하는 코드입니다.- 이 리스트 자체는 힙(Heap)이라는 공간에 저장됩니다.
- 변수
data는 힙에 있는 리스트를 가리키는 주소(참조)입니다.
-
make_list()함수가 호출되면,data는 스택에 저장되지만, 실제 리스트 값[1, 2, 3]은 힙에 만들어집니다.
-
함수가 끝나면
data라는 변수는 사라지고,- 더 이상
[1, 2, 3]을 가리키는 참조가 없으면, - 파이썬의 가비지 컬렉터(Garbage Collector)가 힙에서 자동으로 그 데이터를 지워줍니다.
- 더 이상
파이썬은 더 이상 사용되지 않는 데이터(예: 리스트)를 자동으로 힙 메모리에서 제거함으로써 메모리를 효율적으로 관리합니다.
</> 코드설명:
def test():
data = [10, 20, 30]
print("함수 안:", data)
- 여기서
data리스트는 힙 메모리에 저장됩니다. - 함수 실행 중에는
data를 사용할 수 있지만, test()함수가 끝나면,data는 스택 메모리에서 사라지고,- 리스트
[10, 20, 30]은 더 이상 누구도 참조하지 않게 됩니다.
import gc
gc.collect()
- 이 줄은 파이썬에게 "필요 없는 메모리 정리해!"라고 요청하는 것이고,
- 실제로는 이걸 안 써도 대부분의 경우 파이썬이 자동으로 수행합니다.
- 하지만 직접
gc.collect()를 쓰면 즉시 가비지 컬렉션을 실행합니다.
🔍해설:
data = [10, 20, 30]→ 힙에 리스트 저장됩니다.- 함수 종료 후
data변수는 사라짐 → 리스트는 더 이상 참조되지 않습니다. gc.collect()는 가비지 컬렉터에게 “필요 없는 메모리 정리해줘”라고 요청합니다- 참조가 없어진 리스트는 자동으로 메모리에서 제거(clean up)됩니다.
📝 문제1] 함수가 호출될 때 임시로 사용하는 메모리 공간은 무엇인가요?
① 코드 영역
② 데이터 영역
③ 힙 영역
④ 스택 영역
✅ 정답: ④ 스택 영역
🔍 해설:
- 함수가 호출되면, 함수 안의 지역 변수나 매개변수가 저장되는 공간이 필요합니다.
- 이 임시 공간이 바로 스택(Stack)** 영역이며, 함수가 끝나면 자동으로 제거됩니다.
📝 문제2] 다음 중 힙(Heap) 메모리에 저장되는 데이터는 무엇인가요?
① 함수 이름
② 지역 변수
③ 리스트 객체
④ for문의 반복 변수
✅ 정답: ③ 리스트 객체
🔍 해설:
- 파이썬에서
list,dict,class같은 객체는 동적으로 생성되며 힙에 저장**됩니다. - 지역 변수나 반복 변수는 스택에 저장되며, 함수 실행이 끝나면 사라집니다.
- 리스트처럼 오래 유지되거나 크기가 유동적인 데이터는 힙에서 관리됩니다.
📝 문제3] 스택과 힙에 대한 설명으로 틀린 것은 무엇인가요?
① 스택은 함수 호출 시 자동으로 생성되고 종료되면 사라진다.
② 힙은 사용자가 직접 메모리를 관리해야 하며, 파이썬에서는
가비지 컬렉터가 이를 처리한다.
③ 스택은 후입선출(LIFO) 방식으로 동작한다.
④ 힙에 저장된 데이터는 절대로 자동으로 삭제되지 않는다.
✅ 정답: ④ 힙에 저장된 데이터는 절대로 자동으로 삭제되지 않는다.
🔍 해설:
- 파이썬에서는 힙 메모리에 저장된 데이터도 참조가 사라지면 가비지 컬렉터(GC)에 의해 자동으로 삭제됩니다.
- 즉, 직접 삭제할 필요 없이 자동으로 관리됩니다.
🔹 자료형에 따라 함수에 값이 다르게 전달돼요
파이썬에서 함수를 호출할 때, 넘기는 값이 숫자나 문자열 같은 간단한
값인지, 아니면 리스트나 딕셔너리 같은 복잡한 자료인지에 따라 함수
안에서의 작동 방식이 달라집니다.
이 차이를 이해하지 못하면, 함수 안에서 값을 바꿨을 때
왜 바깥 값도 바뀌었는지 모르고 당황할 수 있어요.
◽ 숫자처럼 간단한 값은 복사(Copy)해서 전달돼요
</> 예시코드:
def change_number(n):
n = n + 10
print("함수 내부:", n)
x = 5
change_number(x)
print("함수 외부:", x)
🖨️ 출력 결과:
함수 내부: 15
함수 외부: 5
- 여기서
x는 숫자니까, 함수에 넘길 때 값 자체가 복사돼서 전달돼요. - 함수 안에서
n이 바뀌어도 원래 x는 바뀌지 않아요.
📘 현업 용어:
이런 자료형은 불변형(immutable type)이라고 불러요.
변경이 불가능한 값들이고, 대표적으로 int, float, str, bool 등이 여기에 속합니다.
◽리스트나 딕셔너리는 참조(Reference)로 전달돼요
</> 예시코드:
def add_item(my_list):
my_list.append(100)
print("함수 내부:", my_list)
nums = [1, 2, 3]
add_item(nums)
print("함수 외부:", nums)
🖨️ 출력 결과:
함수 내부: [1, 2, 3, 100]
함수 외부: [1, 2, 3, 100]
- 여기서는
nums라는 리스트를 함수에 넘겼는데, - 함수 안에서 값을 추가했더니 함수 밖에서도 리스트가 바뀌었어요.
왜냐하면 리스트는 참조(주소)를 넘기기 때문에,
함수 안에서 수정하면 원래 리스트도 같이 바뀌는 거예요.
📘 현업 용어:
이런 자료형은 가변형(mutable type)이라고 해요.
값을 바꿀 수 있고, 여러 곳에서 같은 데이터를 동시에 참조할 수 있어요.
list, dict, set 등이 여기에 포함됩니다.
📝 문제1] 함수 안에서 숫자를 바꾸면 바깥 숫자도 바뀔까요?
# 숫자(정수)를 함수에 넘겨서 값을 바꿔보세요.
# 바깥 변수 x에는 영향이 있는지 확인해보세요.
def modify(n):
n += 5
print("함수 내부:", n)
x = 10
modify(x)
print("함수 외부:", x)
🖨️ 출력 결과:
함수 내부: 15
함수 외부: 10
🔍 해설:
- 숫자(int)는 불변형 자료형(immutable)이라서 함수에 넘기면 값이 복사되어 전달됩니다.
- 함수 내부에서 값을 바꿔도 외부 변수에는 영향이 없습니다.
📝 문제2] 함수에서 리스트를 수정하면 바깥도 바뀔까요?
# 리스트를 함수에 넘기고, 값을 추가해보세요.
# 함수 밖의 리스트도 같이 바뀌는지 확인해보세요.
def add_value(lst):
lst.append(100)
print("함수 내부:", lst)
nums = [1, 2, 3]
add_value(nums)
print("함수 외부:", nums)
🖨️ 출력 결과:
함수 내부: [1, 2, 3, 100]
함수 외부: [1, 2, 3, 100]
🔍 해설:
- 리스트(list)는 가변형 자료형(mutable)이기 때문에 함수에 넘기면 참조 (주소)가 전달됩니다.
- 그래서 함수 안에서 바꾸면 함수 밖의 리스트도 같이 바뀝니다.
📝 문제3] 문자열을 함수에서 바꾸면 외부도 바뀔까요?
# 문자열을 함수에 넘기고, 내용을 바꿔보세요.
# 함수 밖 문자열은 영향을 받을까요?
def change_text(msg):
msg = msg + "!!!"
print("함수 내부:", msg)
text = "Hello"
change_text(text)
print("함수 외부:", text)
🖨️ 출력 결과:
함수 내부: Hello!!!
함수 외부: Hello
🔍 해설:
- 문자열(str)은 불변형 자료형입니다.
- 함수 안에서 문자열을 바꾸면 새로운 문자열이 만들어지고,
기존 문자열에는 아무런 영향을 주지 않습니다.
💭직접 풀어보세요.
📝 문제 1] 튜플 언패킹으로 여러 값 반환 받기
두 숫자의 합과 곱을 동시에 반환하는 함수를 만들어보세요.
반환된 값을 튜플 언패킹으로 각각 변수에 저장하고 출력해보세요.
✔️ 의사코드:
1. 함수에서 두 수를 받아 합과 곱을 계산
2. 합과 곱을 튜플 형태로 반환
3. 함수를 호출해서 두 개의 변수에 각각 저장
4. 출력
🖨️ 출력 결과:
합: 9, 곱: 20
✅ 정답 코드:
def calculate(a, b):
return a + b, a * b
sum_result, mul_result = calculate(4, 5)
print("합:", sum_result, "곱:", mul_result)
🔍 해설:
- 함수는 여러 값을 튜플로 한 번에 반환할 수 있음
- 언패킹을 통해 결과를 각각의 변수에 나눠 저장함
📝 문제 2] 람다 함수로 리스트 정렬 이름과 점수가 들어 있는 튜플 리스트를 점수 기준으로 내림차순 정렬해보세요.
✔️ 의사코드:
1. (이름, 점수) 튜플 리스트 생성
2. sorted() 함수와 lambda를 사용해 점수 기준으로 정렬
3. 출력
🖨️ 출력 결과:
[('지수', 95), ('민수', 85), ('철수', 70)]
✅ 정답 코드:
students = [("철수", 70), ("지수", 95), ("민수", 85)]
sorted_students = sorted(students, key=lambda x: x[1], reverse=True)
print(sorted_students)
🔍 해설:
lambda x: x[1]은 튜플에서 두 번째 값(점수)을 기준으로 정렬reverse=True는 내림차순 옵션
📝 문제 3] 고차 함수로 로그 출력 기능 추가하기 어떤 작업 함수 앞뒤에 로그 메시지를 출력하는 고차 함수(wrap 함수)를 만들어보세요.
✔️ 의사코드:
1. print_log(func) 정의 → 실행 전후 로그 출력
2. 원래 작업 함수(test)를 인자로 넘김
3. print_log로 감싸서 실행
🖨️ 출력 결과:
[LOG] 작업 시작
작업 중입니다...
[LOG] 작업 완료
✅ 정답 코드:
def print_log(func):
def wrapper():
print("[LOG] 작업 시작")
func()
print("[LOG] 작업 완료")
return wrapper
def test():
print("작업 중입니다...")
logged_test = print_log(test)
logged_test()
🔍 해설:
- 고차 함수는 함수를 인자로 받아 새로운 기능을 추가할 수 있음
- 실무에서는 로깅, 에러처리 등에 많이 사용됨
📝 문제 4] with문으로 파일 자동 닫기
텍스트 파일을 만들고, with문을 사용해 파일에 메시지를 작성해보세요.
✔️ 의사코드:
1. 파일을 쓰기 모드(w)로 열기
2. with 문으로 파일 객체 사용
3. 문자열을 write()로 작성
4. 자동으로 닫힘
🖨️ 출력 결과:
(파일 내용) Hello, file!
✅ 정답 코드:
with open("message.txt", "w", encoding="utf-8") as f:
f.write("Hello, file!")
🔍 해설:
with문을 쓰면close()를 따로 호출하지 않아도 됨- 파일 입출력은 실무에서 매우 자주 사용되므로 습관화 필요
📝 문제 5] 제너레이터로 짝수만 생성 0부터 n까지의 숫자 중에서 짝수만 하나씩 생성하는 제너레이터 함수를 만들어보세요.
✔️ 의사코드:
1. 제너레이터 함수 정의 (yield 사용)
2. 0부터 n까지 반복하면서 짝수일 때만 yield
3. for문으로 호출해서 출력
🖨️ 출력 결과:
0
2
4
6
✅ 정답 코드:
def even_numbers(n):
for i in range(n + 1):
if i % 2 == 0:
yield i
for num in even_numbers(6):
print(num)
🔍 해설:
yield를 사용하면 데이터를 하나씩 생성할 수 있음 → 메모리 효율 ↑- 반복문과 함께 쓰면 일반 리스트처럼 순회 가능
📝 문제 6] 함수에 자료형 따라 전달 방식 실습
정수와 리스트를 각각 함수에 넘기고, 함수 내부에서 값을 변경해보세요.
그 결과가 함수 외부에도 영향을 주는지 확인해보세요.
✔️ 의사코드:
1. 숫자와 리스트를 각각 함수에 넘김
2. 숫자는 +=, 리스트는 append
3. 함수 밖에서 결과 비교
🖨️ 출력 결과:
[정수] 내부: 15, 외부: 10
[리스트] 내부: [1, 2, 3, 100], 외부: [1, 2, 3, 100]
✅ 정답 코드:
def change_number(n):
n += 5
print("[정수] 내부:", n)
def change_list(lst):
lst.append(100)
print("[리스트] 내부:", lst)
x = 10
nums = [1, 2, 3]
change_number(x)
print("[정수] 외부:", x)
change_list(nums)
print("[리스트] 외부:", nums)
🔍 해설:
- 정수는 값이 복사되어 전달되므로 외부 변수에 영향 없음
- 리스트는 참조가 전달되므로 내부 변경이 외부에도 반영됨
- 이 차이를 모르면 원하지 않는 데이터 변경이 발생할 수 있음
📝 문제 7] 튜플 언패킹으로 CSV 데이터 나누기 CSV 한 줄 데이터를 튜플로 받아 이름과 나이를 각각 변수로 저장하고 출력해보세요.
1. 튜플 ("홍길동", 30)을 변수 2개로 나눈다
2. 이름과 나이를 각각 출력한다
🖨️ 출력 결과:
이름: 홍길동
나이: 30
✅ 정답 코드:
person = ("홍길동", 30)
name, age = person
print("이름:", name)
print("나이:", age)
🔍 해설:
- 튜플은 여러 값을 묶을 수 있음
- 언패킹을 사용하면 각각의 값을 한 줄로 나눠 변수에 할당 가능함
📝 문제 8] 람다 함수로 문자열 정렬하기 문자열 리스트를 길이순으로 정렬하되, 길이가 같으면 알파벳 순으로 정렬하세요.
✔️ 의사코드
1. 문자열 리스트 생성
2. lambda로 (len(x), x)를 기준으로 정렬
3. 결과 출력
🖨️ 출력 결과:
['an', 'as', 'be', 'cat', 'dog']
✅ 정답 코드:
words = ["dog", "an", "cat", "as", "be"]
sorted_words = sorted(words, key=lambda x: (len(x), x))
print(sorted_words)
🔍 해설:
- 여러 기준으로 정렬할 때
lambda x: (기준1, 기준2)사용 - 이중 기준 정렬은 실무에서도 자주 사용됨 (예: 정렬 우선순위 지정)
📝 문제 9] 고차 함수로 문자열 처리기 만들기 문자열을 대문자 또는 소문자로 처리하는 함수를 만들어, 다른 함수에 전달해서 적용하세요.
✔️ 의사코드
1. 텍스트와 처리 함수를 인자로 받는 high_order_func 만들기
2. 대문자 변환 함수, 소문자 변환 함수 정의
3. high_order_func에 전달해서 결과 출력
🖨️ 출력 결과:
HELLO WORLD
hello world
✅ 정답 코드:
def process_text(text, func):
return func(text)
print(process_text("Hello World", str.upper))
print(process_text("Hello World", str.lower))
🔍 해설:
str.upper,str.lower는 문자열 처리 함수- 고차 함수는 이런 함수를 매개변수로 받아 유연하게 처리할 수 있음
📝 문제 10] with문 없이 파일을 열고 실수 찾기
open()과 close()를 사용해 텍스트 파일에서 실수(3.14)가 포함된 줄만 찾아 출력하세요.
✔️ 의사코드
1. open으로 파일 열기
2. 한 줄씩 읽으며 '3.14'가 포함된 줄만 출력
3. close로 파일 닫기
🖨️ 출력 결과:
파이 값은 3.14입니다.
✅ 정답 코드:
f = open("data.txt", "r", encoding="utf-8")
for line in f:
if "3.14" in line:
print(line.strip())
f.close()
🔍 해설:
with없이 사용할 경우 반드시close()를 직접 호출해야 함.strip()은 줄 끝의\n제거
📝 문제 11] 제너레이터로 로그 파일 필터링
log.txt 파일에서 "ERROR"가 포함된 줄만 제너레이터로 읽어 출력해보세요.
✔️ 의사코드
1. log_reader 제너레이터 함수 만들기
2. "ERROR"가 있는 줄만 yield
3. for문으로 출력
🖨️ 출력 결과:
[ERROR] 디스크 부족
[ERROR] 연결 실패
✅ 정답 코드:
def log_reader(filename):
with open(filename, "r", encoding="utf-8") as f:
for line in f:
if "ERROR" in line:
yield line.strip()
for entry in log_reader("log.txt"):
print(entry)
🔍 해설:
- 제너레이터는 메모리를 아끼며 조건에 맞는 줄만 처리할 수 있음
- 실무에서 로그 파일 분석, 대용량 데이터 처리 등에 유용함
📝 문제 12] 자료형에 따라 함수 호출 결과가 달라지는지 확인 정수와 리스트를 함수에 넘겨 내부에서 수정하고 외부 변수의 변화를 확인하세요.
✔️ 의사코드
1. 숫자 변수와 리스트를 각각 함수에 전달
2. 숫자는 +=5, 리스트는 append 사용
3. 함수 밖에서도 값 비교 출력
🖨️ 출력 결과:
[정수] 내부: 15, 외부: 10
[리스트] 내부: [1, 2, 3, 100], 외부: [1, 2, 3, 100]
✅ 정답 코드:
def change_number(n):
n += 5
print("[정수] 내부:", n)
def change_list(lst):
lst.append(100)
print("[리스트] 내부:", lst)
x = 10
nums = [1, 2, 3]
change_number(x)
print("[정수] 외부:", x)
change_list(nums)
print("[리스트] 외부:", nums)
🔍 해설:
int는 불변형이라 값이 복사되어 함수에 전달됨list는 가변형이라 참조가 전달되므로 외부 값도 바뀜
📝 문제 13] 함수에서 튜플을 받아 직원 정보 출력하기
직원 정보를 담은 튜플 (이름, 부서, 직급)을 받아, 함수에서 각각 나눠 출력해보세요.
✔️ 의사코드:
1. 튜플로 (이름, 부서, 직급) 구성
2. 함수에 넘겨 언패킹
3. 각 항목을 보기 좋게 출력
🖨️ 출력 결과:
이름: 김유진
부서: 개발팀
직급: 주임
✅ 정답 코드:
def print_employee(info):
name, dept, level = info
print("이름:", name)
print("부서:", dept)
print("직급:", level)
employee = ("김유진", "개발팀", "주임")
print_employee(employee)
🔍 해설:
- 튜플은 여러 값을 묶어 하나의 단위로 다룰 수 있음
- 함수 내부에서 언패킹을 통해 변수에 분리 가능
📝 문제 14] 람다로 문자열에서 숫자만 추출하기 문자열 리스트에서 숫자만 있는 항목만 추출해보세요.
✔️ 의사코드:
1. 문자열 리스트 정의
2. filter와 lambda를 사용해 숫자인 문자열만 걸러냄
3. 결과 출력
🖨️ 출력 결과:
['123', '2024']
✅ 정답 코드:
data = ["hello", "123", "world", "2024"]
nums = list(filter(lambda x: x.isdigit(), data))
print(nums)
🔍 해설:
filter()는 조건을 만족하는 항목만 남김lambda x: x.isdigit()은 문자열이 숫자인지 확인
📝 문제 15] 고차 함수로 리스트 데이터 정리기능 만들기 숫자 리스트를 가공하는 함수(예: 제곱, 절댓값 등)를 고차 함수에 넘겨 사용해보세요.
✔️ 의사코드:
1. 고차 함수 정의: 리스트와 함수 받기
2. 넘겨진 함수로 각 요소 처리
3. 새 리스트 반환
🖨️ 출력 결과:
[1, 4, 9]
[3, 2, 5]
✅ 정답 코드:
def apply_all(data, func):
return [func(x) for x in data]
numbers = [1, 2, 3]
print(apply_all(numbers, lambda x: x ** 2)) # 제곱
print(apply_all(numbers, lambda x: abs(x - 4))) # 4와의 거리
🔍 해설:
- 고차 함수는 함수를 인자로 받는 함수
- 유연하게 다양한 데이터 처리를 가능하게 해줌
📝 문제 16] 파일을 열고 특정 단어가 포함된 줄 수 세기 텍스트 파일에서 "python"이 포함된 줄이 몇 개인지 세어보세요.
✔️ 의사코드:
1. 파일 열기 (with 사용)
2. 각 줄 반복하면서 "python" 포함 여부 확인
3. 카운트 증가
🖨️ 출력 결과:
'python'이 포함된 줄 수: 3
✅ 정답 코드:
count = 0
with open("example.txt", "r", encoding="utf-8") as f:
for line in f:
if "python" in line.lower():
count += 1
print("'python'이 포함된 줄 수:", count)
🔍 해설:
- 텍스트 검색은 실무에서 로그 분석, 데이터 필터링 등에 사용됨
with를 통해 자동으로 파일 닫힘 처리됨
📝 문제 17] 제너레이터로 큰 수만 거르기 숫자 리스트에서 100보다 큰 수만 하나씩 반환하는 제너레이터를 만들어보세요.
✔️ 의사코드:
1. 제너레이터 함수 정의
2. if 조건으로 100 이상이면 yield
3. for문으로 꺼내 출력
🖨️ 출력 결과:
150
300
✅ 정답 코드:
def filter_large(numbers):
for n in numbers:
if n >= 100:
yield n
data = [50, 150, 80, 300]
for num in filter_large(data):
print(num)
🔍 해설:
yield는 데이터를 하나씩 꺼내는 제너레이터 키워드- 대용량 리스트나 조건 필터링에 적합
📝 문제 18] 힙 객체를 삭제하고 메모리 정리하기
리스트 객체를 만든 뒤 참조를 제거하고 gc 모듈을 사용해 메모리를 수동 정리해보세요.
✔️ 의사코드:
1. 리스트 생성
2. 리스트 참조 제거
3. gc.collect()로 가비지 수집 요청
🖨️ 출력 결과:
가비지 수집 완료
✅ 정답 코드:
import gc
def create_data():
data = [i for i in range(100000)]
return data
my_data = create_data()
del my_data # 참조 제거
gc.collect()
print("가비지 수집 완료")
🔍 해설:
- 리스트 등 객체는 힙에 저장됨
- 참조가 없으면 가비지 컬렉터가 정리함
gc.collect()는 수동으로 메모리 정리를 요청할 수 있음
📝 문제 19] 튜플 리스트에서 특정 조건에 맞는 항목 찾기
직원 정보 리스트에서 "마케팅팀"에 속한 사람만 출력해보세요.
직원 정보는 (이름, 부서) 형식의 튜플로 구성되어 있습니다.
✔️ 의사코드:
1. 직원 리스트 정의 (이름, 부서 튜플)
2. for문으로 하나씩 반복
3. 부서가 "마케팅팀"이면 출력
🖨️ 출력 결과:
마케팅팀 직원: 이지은
✅ 정답 코드:
employees = [("김민수", "개발팀"), ("이지은", "마케팅팀"), ("박지후", "디자인팀")]
for name, dept in employees:
if dept == "마케팅팀":
print("마케팅팀 직원:", name)
🔍 해설:
- 튜플 리스트에서 반복하면서 언패킹하여 이름과 부서를 나눔
- 특정 조건에 맞는 항목을 선별하는 기본 패턴은 실무 필터링 작업에서 자주 사용됨
📝 문제 20] 람다를 활용해 특정 패턴으로 문자열 변환
문자열 리스트를 모두 "Hello, ___!" 형태로 변환해보세요.
✔️ 의사코드:
1. 이름 리스트 정의
2. map과 lambda를 이용해 "Hello, 이름!" 형태로 변환
3. 리스트로 결과 출력
🖨️ 출력 결과:
['Hello, Alice!', 'Hello, Bob!', 'Hello, Charlie!']
✅ 정답 코드:
names = ["Alice", "Bob", "Charlie"]
greetings = list(map(lambda x: f"Hello, {x}!", names))
print(greetings)
🔍 해설:
map()과lambda조합은 반복적인 문자열 처리에 유용f-string으로 문자열 포맷팅을 간단하게 처리함
📝 문제 21] 고차 함수로 로그 기능 추가된 출력 함수 만들기
출력 전에 [INFO]를 자동으로 붙여주는 래퍼 함수를 만들어보세요.
✔️ 의사코드:
1. log_wrapper(func)를 정의
2. 전달된 함수 실행 전 "[INFO]" 출력
3. 원래 함수 호출
🖨️ 출력 결과:
[INFO] 다음 메시지를 출력합니다.
안녕하세요!
✅ 정답 코드:
def log_wrapper(func):
def wrapped():
print("[INFO] 다음 메시지를 출력합니다.")
func()
return wrapped
def say_hello():
print("안녕하세요!")
logged = log_wrapper(say_hello)
logged()
🔍 해설:
- 고차 함수로 동작 전후에 기능을 추가할 수 있음
- 실무에서는 로깅, 예외처리, 인증 검사 등에 응용 가능
📝 문제 22] 파일에서 특정 키워드가 포함된 줄 번호 찾기
텍스트 파일에서 "ERROR"가 들어간 줄 번호만 출력해보세요. (첫 줄은 1번)
✔️ 의사코드:
1. 파일 열기 (with 사용)
2. enumerate로 줄 번호와 내용 함께 반복
3. "ERROR" 포함되면 줄 번호 출력
🖨️ 출력 결과:
ERROR 발견: 2번째 줄
ERROR 발견: 5번째 줄
✅ 정답 코드:
with open("log.txt", "r", encoding="utf-8") as f:
for idx, line in enumerate(f, 1):
if "ERROR" in line:
print(f"ERROR 발견: {idx}번째 줄")
🔍 해설:
enumerate()는 반복문에서 인덱스와 값 동시 사용- 로그 파일 분석, 오류 라인 추적 등에 실무 적용 가능
📝 문제 23] 제너레이터로 특정 문자열만 필터링 출력하기 리스트에서 길이가 5 이상인 문자열만 하나씩 출력하는 제너레이터를 만들어보세요.
✔️ 의사코드:
1. 제너레이터 함수 정의
2. 리스트 반복하며 길이 5 이상인 문자열만 yield
3. for문으로 출력
🖨️ 출력 결과:
banana
grapes
orange
✅ 정답 코드:
def long_words(words):
for word in words:
if len(word) >= 5:
yield word
items = ["kiwi", "banana", "grapes", "fig", "orange"]
for word in long_words(items):
print(word)
🔍 해설:
- 조건 필터링 제너레이터는 필요한 데이터만 효율적으로 추출할 수 있음
- 메모리 낭비 없이 반복적으로 사용할 수 있음
📝 문제 24] 함수에 리스트를 넘기고 원본 보호하기 리스트를 함수에 넘겨도 원본 리스트를 변경하지 않도록 함수 내부에서 복사해서 처리해보세요.
✔️ 의사코드:
1. 리스트를 함수에 넘김
2. 내부에서 복사본 생성 (copy 사용)
3. 복사본만 수정 후 출력
4. 외부 리스트는 그대로 유지됨
🖨️ 출력 결과:
함수 내부: [1, 2, 3, 100]
함수 외부: [1, 2, 3]
✅ 정답 코드:
def safe_append(data):
copy = data.copy()
copy.append(100)
print("함수 내부:", copy)
nums = [1, 2, 3]
safe_append(nums)
print("함수 외부:", nums)
🔍 해설:
- 리스트는 참조로 전달되기 때문에 직접 수정하면 원본도 바뀜
.copy()로 복사본을 만들면 원본 보호 가능- 실무에서 데이터 가공 시 매우 중요한 개념
📝 문제 25] 튜플을 이용해 좌표 데이터 다루기
(x, y) 좌표 튜플이 주어졌을 때, 각 좌표를 나눠서 출력해보세요.
✔️ 의사코드:
1. 좌표 튜플을 정의한다
2. 튜플을 언패킹해서 x, y 변수에 저장한다
3. x와 y 좌표를 각각 출력한다
🖨️ 출력 결과:
x좌표: 12
y좌표: 5
✅ 정답 코드:
point = (12, 5)
x, y = point
print("x좌표:", x)
print("y좌표:", y)
🔍 해설:
- 튜플은 여러 값을 묶을 수 있는 자료형
- 언패킹을 사용하면 각각의 값을 쉽게 분리해 사용할 수 있음
📝 문제 26] 람다와 sorted를 활용해 복잡한 기준으로 정렬하기
리스트 안에 (제품명, 가격) 튜플이 있는 구조입니다. 가격이 같다면 이름순으로 정렬해보세요.
✔️ 의사코드:
1. (이름, 가격) 튜플로 구성된 리스트 정의
2. lambda를 이용해 (가격, 이름) 순서로 정렬
3. 정렬된 결과를 출력
🖨️ 출력 결과:
[('귤', 2000), ('사과', 2000), ('포도', 2500)]
✅ 정답 코드:
products = [("사과", 2000), ("포도", 2500), ("귤", 2000)]
sorted_products = sorted(products, key=lambda x: (x[1], x[0]))
print(sorted_products)
🔍 해설:
- 다중 조건 정렬은
(기준1, 기준2)튜플을 사용하면 간단하게 처리 가능 lambda를 이용한sorted()는 실무에서 자주 활용됨
📝 문제 27] 고차 함수를 활용한 텍스트 포맷터 만들기 문자열 앞뒤에 꾸밈 기호를 추가하는 함수들을 만들어, 고차 함수로 전달해보세요.
✔️ 의사코드:
1. 텍스트 꾸미기 함수 두 개 정의 (*추가, -추가)
2. 고차 함수 format_text(func, text) 정의
3. 각각의 꾸미기 함수 전달해서 사용
🖨️ 출력 결과:
*hello*
-hello-
✅ 정답 코드:
def add_stars(text):
return f"*{text}*"
def add_dashes(text):
return f"-{text}-"
def format_text(func, text):
return func(text)
print(format_text(add_stars, "hello"))
print(format_text(add_dashes, "hello"))
🔍 해설:
- 고차 함수는 함수를 인자로 받아 기능을 유연하게 확장할 수 있음
- 실무에서 포맷 처리, 필터링, 콜백 구성 등에 활용됨
📝 문제 28] 파일에서 특정 단어가 있는 줄 번호와 내용을 함께 출력
log.txt 파일에서 "warning"이 포함된 줄의 줄 번호와 내용을 함께 출력해보세요.
✔️ 의사코드:
1. 파일을 읽기 모드로 연다
2. enumerate로 줄 번호와 내용을 동시에 얻는다
3. 줄에 "warning"이 포함되었으면 출력한다
🖨️ 출력 결과:
3번째 줄: Disk warning occurred.
7번째 줄: Warning: memory usage high.
✅ 정답 코드:
with open("log.txt", "r", encoding="utf-8") as f:
for idx, line in enumerate(f, 1):
if "warning" in line.lower():
print(f"{idx}번째 줄:", line.strip())
🔍 해설:
enumerate()는 줄 번호와 함께 내용을 반복할 수 있게 함.lower()를 통해 대소문자 구분 없이 검색 가능- 실무에서는 로그 분석, 키워드 추출에 자주 사용
📝 문제 29] 제너레이터를 활용해 짝수만 걸러내는 반복기 만들기 숫자 리스트에서 짝수만 하나씩 반환하는 제너레이터를 만들어 출력해보세요.
✔️ 의사코드:
1. 숫자 리스트를 매개변수로 받는 제너레이터 함수 정의
2. 짝수인 경우에만 yield로 넘긴다
3. for문으로 하나씩 출력
🖨️ 출력 결과:
2
4
8
✅ 정답 코드:
def even_filter(data):
for num in data:
if num % 2 == 0:
yield num
numbers = [1, 2, 3, 4, 7, 8]
for n in even_filter(numbers):
print(n)
🔍 해설:
- 제너레이터는 조건에 맞는 값만 하나씩 처리할 수 있어 효율적
- 필터링 로직을 반복 가능한 객체로 만들 수 있음
📝 문제 30] 불필요한 참조 제거 후 수동으로 메모리 정리하기
리스트를 생성한 후 del로 참조를 제거하고 gc.collect()로 메모리를 정리해보세요.
✔️ 의사코드:
1. 큰 리스트를 생성하고 변수에 저장
2. del로 변수 삭제
3. gc.collect() 호출
🖨️ 출력 결과:
가비지 수집 완료
✅ 정답 코드:
import gc
data = [i for i in range(100000)]
del data
gc.collect()
print("가비지 수집 완료")
🔍 해설:
del은 변수의 참조를 해제gc.collect()는 사용되지 않는 메모리를 수동으로 수집- 파이썬의 힙 관리와 가비지 컬렉터 동작 이해에 유용함